Oracle 关系数据库
Table of Contents
1 数据库概述
Oracle Database,又名 Oracle RDBMS,或简称 Oracle。是甲骨文公司的一款关系数据 库管理系统。它是在数据库领域一直处于领先地位的产品。可以说 Oracle 数据库系统是 目前世界上流行的关系数据库管理系统,系统可移植性好、使用方便、功能强,适用于各 类大、中、小、微机环境。它是一种高效率、可靠性好的、适应高吞吐量的数据库解决方 案。
1.1 数据库和实例
- 数据库 (Database) 指的是存放于磁盘中的一系列文件,数据库是独立于数据库实例
- 数据库实例 (Database Instance) 指定是用于管理数据库文件的一系列内存数据结
构。实例包含:
- SGA (System Global Area) 全局共享内存
- PGA (Program Global Area) 每个 Client 都有自己私有的会话内存
- Background Processes 后台进程
下图展示了 Oracle 的数据库和 Client Process 交互的细节
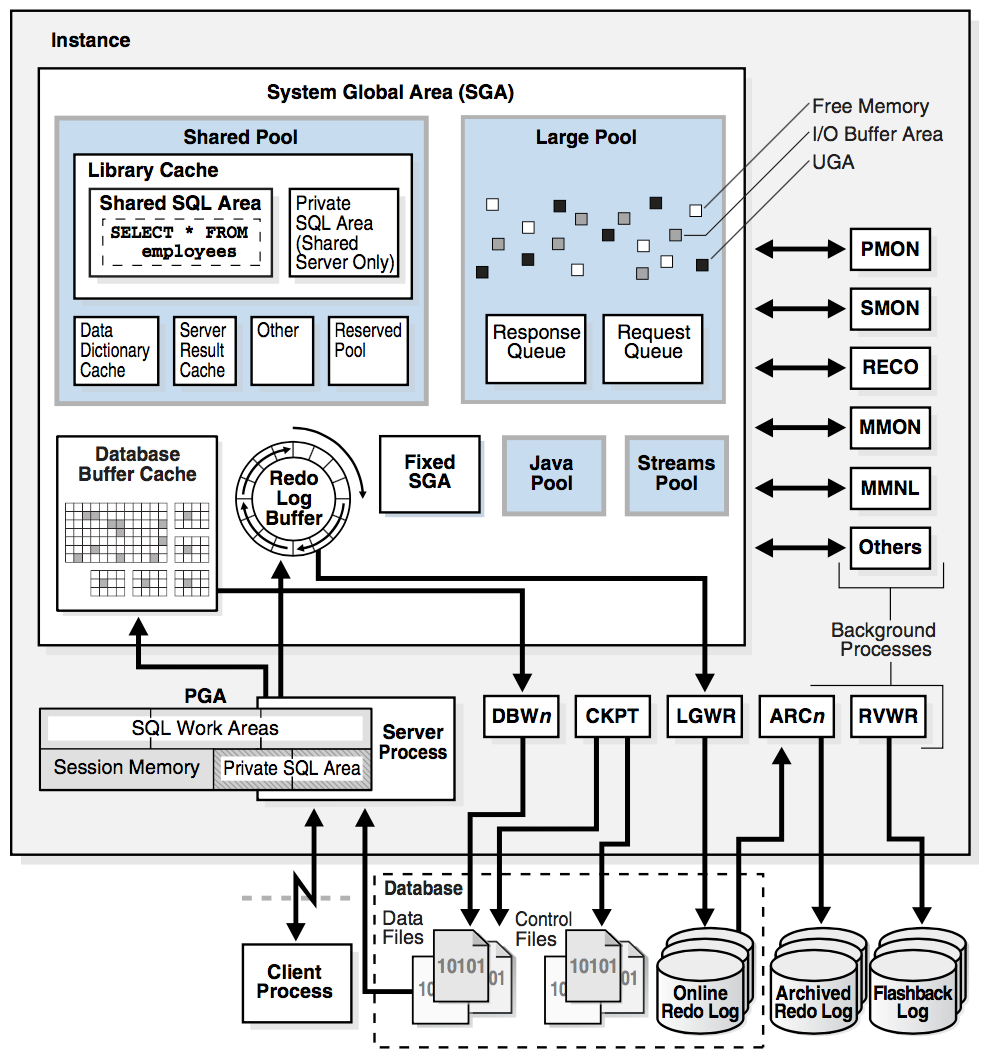
1.2 数据存储结构
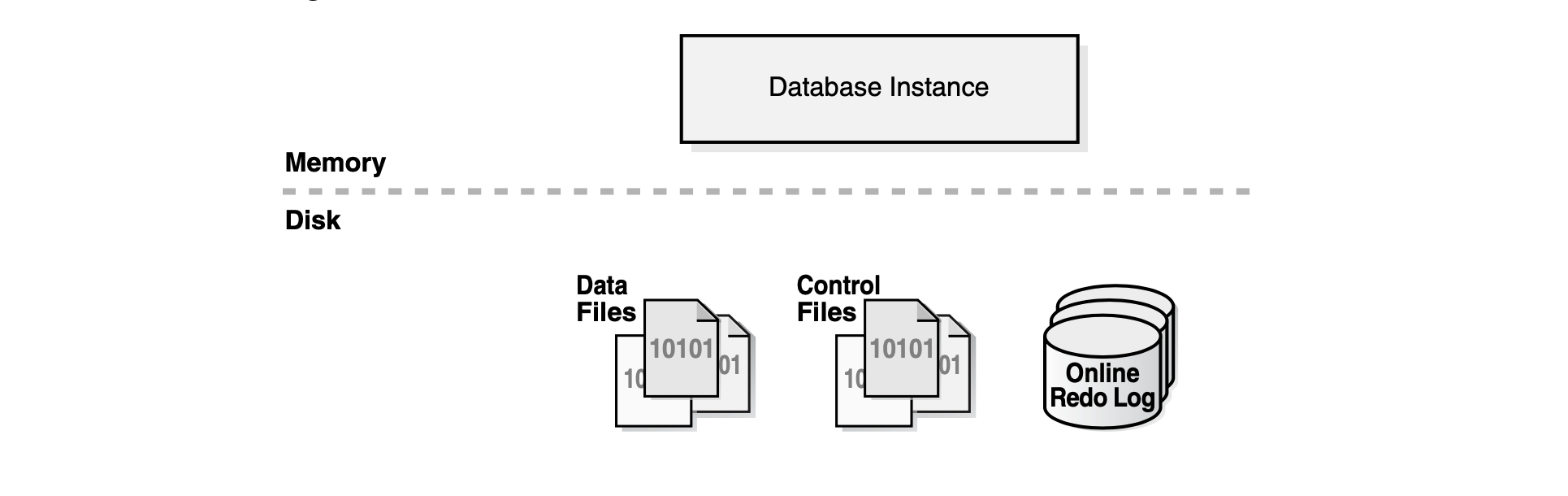
数据存可以分成物理存储好逻辑存储两个部分,两者的联系见下图
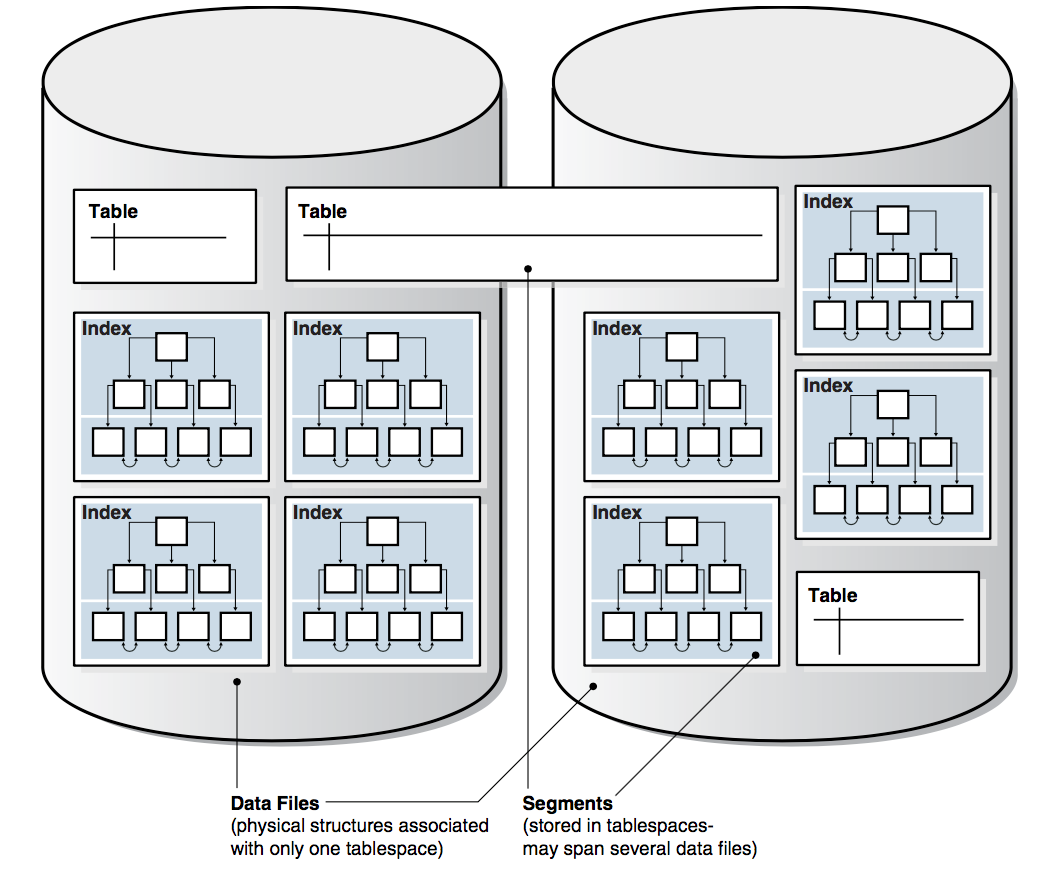
物理存储结构当执行 CREATE DATABASE 时,下面的文件将被创建
- 数据文件 (Data Files) 包含所有的数据库的数据,数据的逻辑结构例如表、索引 都是存储在数据文件
- 控制文件 (Control Files) 包含物理结构的一些元信息,例如:数据库名称和数据 库文件的路径
- 重做日志 (Online Redo Log Files) 包含重做的日志文件,每个重做日志由一系列 的 Redo Entires (也被称为 Redo Records)组成
- 还一些其他的物理文件 例如:Parameter Files, Diagnostic Files, Backup Files, Archived Redo Log Files 等
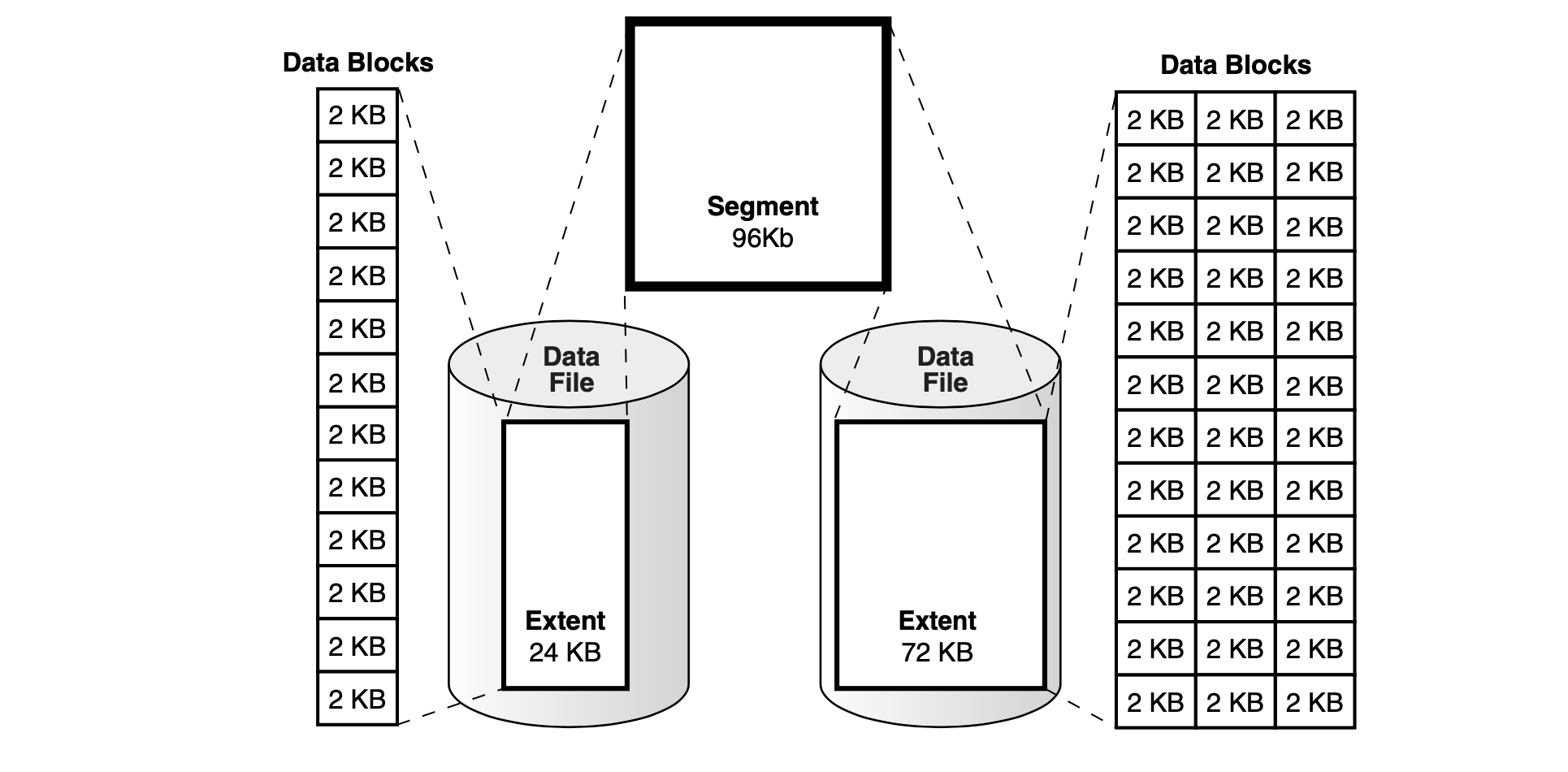
逻辑存储逻辑结构是存储在一系列 Data Blocks 中
- 块 (Data Blocks) 由定长字节的文件组成的二进制文件
- 区 (Extents) 由定长的逻辑连续 Data Blocks 构成。Extends 一次性分配,用来 存储特定类型的信息
- 段 (Segments) 由一系列的 Extents 构成,可以对应一些用户的对象,例如:表、 索引、Undo Data 和 Temporary Data
- 表空间 (Tablespace) 一个 Database 被分成多个逻辑的 Tablespace 单元。 Tablespace 是 Segments 的逻辑容器。
1.3 数据库实例结构
数据库实例是使用内存数据结构和进程来管理数据库,当应用需要连接数据库时,它将 会首先连接到一个数据库实例中
1.3.1 Oracle 数据进程
Oracle Processes 包括 Server Processes 和 Background Processes。大多数情况下, Oracle Processes 和 Client Processes 运行在不同电脑中。 Oracle 数据库在启动 时会启动一系列的数据库实例
- Client Processes 用来运行软件或 Oracle 工具,大部分运行环境是在不同电脑上
- Background Processes 用来处理多个 Oracle 数据库程序,可以进行异步 I/O 或者 监控其它 Oracle 数据库。
- Server Processes 和 Client Processes 与 Oracle 数据库交互,用来完成处理请求
1.3.2 实例内存结构
- SGA 是包含一个数据库实例的数据和控制信息的一组共享内存的。例如:SGA 包含 Cached Data Blocks 和 Shared SQL Area
- PGA 是包含一个 Background Processes 和 Server Processes 实例的数据和控制信 息的一组内存区域
2 关系数据结构
2.1 数据库和表
2.1.1 创建表
CREATE TABLE [scmname.]tabname ( colname DBTYPE [NOT NULL | NULL] [DEFAULT DEFAULT_VALUE] [PRIMARY KEY] );
- Oracle 数据库中
scmname,tabname, 和colname不加引号默认大写,即使 使用小写的名称也会自动转成大写。如果非要使用小写需要使用单引号将名称包起来 - Oracle 一张表最多只能有 254 列
- dbtype 是数据类型,Oracle 数据库中常见的有 number, varchar2, date,布尔型一
般使用
char(1)或number(1)来模拟
简单的用户表创建
CREATE TABLE USERS ( ID NUMBER(16) PRIMARY KEY NOT NULL, CREATED_BY VARCHAR2(64) DEFAULT 'SYSMAN' NOT NULL, UPDATED_AT DATE DEFAULT SYSDATE NOT NULL, VALID CHAR(1) DEFAULT 'Y' NOT NULL, -- CODE RULE AND TYPE CODE VARCHAR2(32) UNIQUE NOT NULL, NAME VARCHAR2(32) ); COMMENT ON COLUMN USERS.CODE IS '用户编号, 用于登录'; COMMENT ON COLUMN USERS.NAME IS '用户名字, 用于显示';
2.1.2 数据类型
- 数值型
number(precision[,scale]): 数值型,用于表示整数和实数。 precision 表示 精度,scale 表示数值范围。precision 的取值范围为 1 到 38,scale 的取值范 围为 -84 到 127。一句话: precision 是总的数字位数, scale 是小数点后的数 字个数
- 字符串
varchar2(size[byte|char]): 变长字符串类型,size 表示字符串最大长度,单 位可以是 byte 或 char。 size 的取值范围为 1 到 4000。单位 byte 表示所用的 字节数,单位 char 表示所用的字符(character)数nvarchar2(size): 边长 unicode 编码字符串类型,AL16UTF16字符编码的 byte 数是utf8字符编码的三倍,所以 nvarchar2 的 size 取决于具体的编码 集。size 的取值范围为 1 到 4000char(size[byte|char]): 定长字符串类型,size 的取值范围是 1 到 2000 。 单位 byte 和单位 char 语义一样都是表示字符(character)数long: 2gb 的超长字符串。 每张表只允许一列是 long 类型
注意 数据库中的
char存储时每个字段大小占用的字节数是固定的,varchar2存储时暂用的字节是变化的。两者使用的场景不同,对于使用字符串固定长度的,例 如:valid 字段,'y'表示合法,'n'表示不合法,可以使用char来存储, 这样访问速度快;大部分的场景:字符串长度是不确定的,而且变化比较大,这时最 好使用varchar2来存储,这样节约存储空间 - 时间/日期类型
date: 时间和日期类型。 Oracle 的时间和日期都用 date 类型表示, 默认的 时间格式字符由NLS_DATE_FORMAT参数决定,它是'DD-MMM-YY'格式,例如:'13-OCT-92','07-JAN-98'
- 二进制 Lob
clob: 最多可以存储 4GB 的数据字符的大对象(Character Data of Large Object)blob: 最多可以存储 4GB 数据的二进制大对象(Binary Large Object)
2.1.3 修改表结构
-- 添加一列 alter table tabname add colname varchar2; comment on column tabname.colname is 'comments'; alter table t_employee_base add column is_active char(1) default 'n'; comment on column t_employee_base.is_active is '用户是否激活,默认为 n,表示未激活'; -- 删除一列 alter table tabname drop column colname; -- 添加主键 alter table tabname add primary key ("pk_name"); -- 重命名列 alter table tabname rename column oldcol to newcol;
2.1.4 查看所有表
-- 查看当前数据库 select name from v$database; -- 查看所有表 select table_name from user_tables order by table_name; -- 查看所有表和视图,以及注释 select a.table_name || ' ' || a.comments from user_tab_comments a where a.table_type in ('table', 'view') order by a.table_name; -- 查看单个表结构 desc tabname;
2.1.5 临时表
临时表主要作用是保存事务或者会话的中间数据,所以一般包含事务级别的和会话级别 的临时表
- 事务级临时表
on commit delete rows当 COMMIT 的时候删除数据(默认情况) - 会话级临时表
on commit preserve rows当 COMMIT 的时候保留数据,当会话结 束删除数据
create global temporary table tabname ( id number ) on commit delete rows;
Oracle 的临时表创建完就是真实存在的,无需每次都创建。 删除临时表和删除普通表 一样
drop table tabname; truncate table tabname;
2.1.6 其它
- Oracle 表默认存储结构是堆 (Heap)
- Oracle 的空值 NULL 不同于字符串,空值在数据库中的存储方式有以下两种:
- 如果 NULL 在两列之间,需要一字节来存储,一般是 ASCII 码 Zero 值
- 如果 NULL 位于行末端,一般默认不存
2.2 索引
索引 (Index) 是数据库的可选的一种数据结构,主要用处是加速数据存取
2.2.1 创建索引
-- 单行索引 create index idxname on tabname(colname); -- 组合索引 create index idxname on tabname(colname1, colname2);
2.2.2 修改和删除索引
-- 重建索引:如果经常在索引列上执行 dml 操作,需要定期重建索引 alter index idxname rebuild; -- 删除索引 drop index idxname;
2.2.3 索引类型
- B-tree Indexes 适合与大量的增删改 (OLTP)
- Bitmap and Bitmap Join Indexes 适合与决策支持系统,做 Update 代价非常高
Funtion-based Indexes 经常对某个字段做查询的时候是带函数操作的
-- 函数索引 create index emp_name_upper_ix on emp (upper(name));
- Application Domain Indexes
2.3 分区,视图,序列等
2.3.1 分区
分区指的是对数据量较大,访问速度较慢的表进行分成几个子区域进行管理。分区表包 含 一个或多个 分区,注意包含一个分区的分区表和不分区表是不同的,包含一个分 区的分区表可以添加新的分区,而不分区表却不能添加新的分区。
分区主要包含以下要素
- 分区键 (Partition Key)
- 分区策略 (Partition Strategies),常见的分区有一下几种
- 基于范围的分区 (Range Partition)
- 基于列表的分区 (List Partition)
- 基于哈希的分区 (Hash Partition)
2.3.2 创建分区表
创建分区表主要是在 create table 语句后面加 partition by 来说明分区策略
基于范围的分区表
CREATE TABLE TIME_RANGE_SALES ( PROD_ID NUMBER (6), -- 产品 ID CUST_ID NUMBER, -- 顾客 ID TIME_ID DATE, -- 时间 ID CHANNEL_ID CHAR(1), -- 渠道 ID PROMO_ID NUMBER(6), QUANTITY_SOLD NUMBER (3), AMOUNT_SOLD NUMBER (10, 2) ) PARTITION BY RANGE (TIME_ID) ( PARTITION SALES_1998 VALUES LESS THAN (TO_DATE('1999-01-01', 'YYYY-MM-DD')), PARTITION SALES_1999 VALUES LESS THAN (TO_DATE('2000-01-01', 'YYYY-MM-DD')), PARTITION SALES_2000 VALUES LESS THAN (TO_DATE('2001-01-01', 'YYYY-MM-DD')), PARTITION SALES_2001 VALUES LESS THAN (MAXVALUE) );
基于列表的分区表
CREATE TABLE LIST_SALES ( PROD_ID NUMBER(6), -- 产品 ID CUST_ID NUMBER, -- 顾客 ID TIME_ID DATE, -- 时间 ID CHANNEL_ID CHAR(1), -- 渠道 ID PROMO_ID NUMBER(6), QUANTITY_SOLD NUMBER (3), AMOUNT_SOLD NUMBER (10, 2) ) PARTITION BY LIST (CHANNEL_ID) ( PARTITION EVEN_CHANNELS VALUES (2, 4), PARTITION ODD_CHANNELS VALUES (3, 9) );
基于哈希的分区表
CREATE TABLE HASH_SALES ( PROD_ID NUMBER(6), -- 产品 ID CUST_ID NUMBER, -- 顾客 ID TIME_ID DATE, -- 时间 ID CHANNEL_ID CHAR(1), -- 渠道 ID PROMO_ID NUMBER(6), QUANTITY_SOLD NUMBER (3), AMOUNT_SOLD NUMBER (10, 2) ) PARTITION BY HASH (PROD_ID) PARTITIONS 2;
2.3.3 分区索引
分区表和不分区表建索引也是不同的。分区表的索引包含全局索引 (Global Indexes) 和局部索引 (Local Indexes)。局部索引根据局部索引策略的不同又分成了 Local Prefixed Indexes 和 Local NonPrefixed Indexes 两类
对于索引有以下几个注意点:
- 分区的列必须是主机列的一个子集
- 第二分区索引可以进行局部分区或者全局分区
- 溢出的数据会被均分到各个分区中,而不会堆积在某一个单独的分区
创建分区表的索引方法如下
-- 创建分区表的局部索引 CREATE INDEX HASH_SALES_IDX ON HASH_SALES (TIME_ID) LOCAL; -- 创建分区表的全局索引 CREATE INDEX TIME_CHANNEL_SALES_IDX ON TIME_RANGE_SALES (CHANNEL_ID) GLOBAL PARTITION BY RANGE (CHANNEL_ID) ( PARTITION P1 VALUES LESS THAN (3), PARTITION P2 VALUES LESS THAN (4), PARTITION P3 VALUES LESS THAN (MAXVALUE) );
2.3.4 视图
视图 (View) 也称虚表, 不占用物理空间,这个也是相对概念,因为视图本身的定义 语句还是要存储在数据字典里的。视图只有逻辑定义。每次使用的时候,只是重新执行 SQL,视图的好处如下:
- 提供各种数据表现形式, 可以使用各种不同的方式将基表的数据展现在用户面前, 以便符合用户的使用习惯 (主要手段: 使用别名);
- 隐藏数据的逻辑复杂性并简化查询语句, 多表查询语句一般是比较复杂的, 而且 用户需要了解表之间的关系, 否则容易写错; 如果基于这样的查询语句创建一个视 图, 用户就可以直接对这个视图进行"简单查询"而获得结果. 这样就隐藏了数据的 复杂
- 执行某些必须使用视图的查询. 某些查询必须借助视图的帮助才能完成. 比如, 有 些查询需要连接一个分组统计后的表和另一表, 这时就可以先基于分组统计的结果 创建一个视图, 然后在查询中连接这个视图和另一个表就可以了
- 提供某些安全性保证. 视图提供了一种可以控制的方式, 即可以让不同的用户看见 不同的列, 而不允许访问那些敏感的列, 这样就可以保证敏感数据不被用户看见;
- 简化用户权限的管理. 可以将视图的权限授予用户, 而不必将基表中某些列的权限 授予用户, 这样就简化了用户权限的定义。
2.3.5 创建视图
简单的创建视图可以暴露源表的某些字段
CREATE VIEW STAFF AS SELECT EMPLOYEE_ID, LAST_NAME, JOB_ID FROM EMPLOYEES;
视图可以封装做一些对源表的数据处理
CREATE VIEW STAFF_DEPT_10 AS SELECT EMPLOYEE_ID, LAST_NAME, JOB_ID FROM EMPLOYEES WHERE DEPARTMENT_ID = 10 WITH CHECK OPTION CONSTRAINT STAFF_DEPT_10_CNST;
合并多个表,给用户暴露一个单一的表
CREATE VIEW STAFF_DEPT_10_30 AS SELECT E.EMPLOYEE_ID, E.LAST_NAME, E.JOB_ID, D.DEPARTMENT_NAME FROM EMPLOYEE E, DEPARTMENT D WHERE E.DEPARTMENT_ID IN (10, 30) AND E.DEPARTMENT_ID = D.DEPARTMENT_ID;
2.3.6 物化视图
物化视图 (Materialized View) 将视图选取的数据进行存储,目的是减少构建视图时 的计算时间,用空间换时间
CREATE MATERIALIZED VIEW SALES_MV AS SELECT T.CALENDAR_YEAR, P.PROD_ID, SUM(S.AMOUNT_SOLD) AS SUM_SALES FROM TIMES T, PRODUCTS P, SALES S WHERE T.TIME_ID = S.TIME_ID AND P.PROD_ID = S.PROD_ID GROUP BY T.CALENDAR_YEAR, P.PROD_ID;
2.3.7 序列
序列可以生成连续的数,主要用于解决数据库并发访问时 ID 值生成策略
-- 创建一个序列 CREATE SEQUENCE CUST_SEQ START WITH 1000 INCREMENT BY 1 NOCACHE NOCYCLE; -- 使用方法 SELECT CUST_SEQ.NEXTVAL FROM DUAL; -- 查看当前序列值 SELECT CUST_SEQ.CURRVAL FROM DUAL;
2.3.8 同义词
同义词定义了数据库结构的别名,可以方便访问。同义词分为 public 和 private 的 两种, public 对所有用户公开, private 针对特定用户
CREATE PUBLIC SYNONYM PEOPLE HR.EMPLOYEES;
2.4 数据完整性
数据完整性 (Data Integrity) 保证存储在数据库中的所有数据值均正确的状态
2.4.1 非空约束
非空 (NOT NULL) 约束限制数据库表列的值不能为 NULL,那么当插入数据时,必须为 列提供,数据不能为 NULL。约束只能在列级定义,不能在表级定义。
建表时指定在对应列后面添加 not null 指定该列为非空
CREATE TABLE EMPLOYEES ( ID NUMBER(16) PRIMARY KEY, CREATED_BY VARCHAR2(64) DEFAULT 'SYSMAN' NOT NULL, -- 指定当前列为非空 NAME VARCHAR2(32) ); -- 给非空约束添加名称 CREATE TABLE EMPLOYEES ( ID NUMBER(16) PRIMARY KEY, CREATED_BY VARCHAR2(64) DEFAULT 'SYSMAN', NAME VARCHAR2(32), CONSTRAINT EMP_CREATED_BY_UK(CREATED_BY) NOT NULL; -- 指定当前列为非空 );
修改列的非空属性
-- 添加非空约束 ALTER TABLE TABNAME MODIFY COLNAME [CONSTRAINT CONSTRAINT_NAME] NOT NULL; -- 删除非空约束 ALTER TABLE TABNAME MODIFY COLNAME NULL;
2.4.2 唯一性约束
唯一性 (Unique) 约束表示该列值是不能重复的,但是可以为 NULL
CREATE TABLE EMPLOYEES ( EMAIL VARCHAR2 (25), CONSTRAINT EMP_EMAIL_NN NOT NULL, -- 非空 CONSTRAINT EMP_EMAIL_UK UNIQUE (EMAIL) -- 唯一键 ); -- 添加唯一键 ALTER TABLE TABNAME ADD CONSTRAINT EMP_EMAIL_UK UNIQUE (EMAIL);
2.4.3 主键约束
用于唯一的标识表行的数据,当定义主键约束后,该列不但不能重复而且不能为 NULL。 一张表最多只能有一个主键,但是可以由多个 Unique 约束。创建主键或唯一约束后, Oracle 会自动创建一个与约束同名的索引 (Uniquenes 为 Unique 唯一索引) 需要注 意的是: 每个表只能有且有一个主键约束
CREATE TABLE EMPLOYEES ( ID NUMBER (16) PRIMARY KEY, -- 主键约束 NAME VARCHAR2 (32) ); CREATE TABLE EMPLOYEES ( ID NUMBER (16), NAME VARCHAR2 (32), CONSTRAINT EMPLOYEE_PK PRIMARY KEY (ID) -- 主键约束 );
2.4.4 外键约束
用于定义主表和从表之间的关系,外键约束要定义在从表上,主要则必须具有主键约束 或是 Unique 约束,当定义外键约束后,要求外键列数据必须在主表的主键列存在或是 为 NULL,即引用完整性 (Referential Integrity)。如果外键作用于当前表本身的列, 则该约束为自引用完整性 (Self-Referential Integrity)
用来维护从表 (Child Table) 和主表 (Parent Table) 之间的引用完整性。外键约束 是个有争议性的约束,它一方面能够维护数据库的数据一致性,数据的完整性。防止错 误的垃圾数据入库; 另外一方面它会增加表插入、更新等 SQL 性能的额外开销,不少 系统里面通过业务逻辑控制来取消外键约束。例如在数据仓库中,就推荐禁用外键约束。
修改外键时的从表行为有以下三种:
- No Action on Deletion and Update, 默认为删除和更新是不操作
- Cascading Deletion, 级联删除
- Deletion that Set NULL, 删除是置空
外键插入、更新或删除形容如下
| DML | 主表 | 从表 |
|---|---|---|
insert |
要求主表键唯一 | 要求外键值在从表中存在,或者包含多行,或者为 NULL |
update no action |
如果从表中没有没有引用主表的的行 | 如果更新后新的外键仍然引用旧的外键 |
delete no action |
如果子表中没有引用主表的行 | 任何情况都可行 |
delete cascade |
任何情况都可行 | 任何情况都可行 |
delete set null |
任何情况都可行 | 任何情况都可行 |
CREATE TABLE DEPARTMENTS ( ID NUMBER (16) PRIMARY KEY ); CREATE TABLE EMPLOYEES ( ID NUMBER (16), DEPT_ID NUMBER (16), -- 添加外键 CONSTRAINT EMP_DEPT_FK FOREIGN KEY (DEPT_ID) REFERENCES DEPARTMENTS (ID) ); -- 修改表,添加外键 ALTER TABLE EMPLOYEES ADD CONSTRAINT EMP_DEPT_FK FOREIGN KEY (DEPT_ID) REFERENCES DEPARTMENTS (ID);
2.4.5 条件约束
条件约束 (check constraint) 用于强制行数据必须满足的条件
ALTER TABLE EMPLOYEES ADD CONSTRAINT MAX_EMP_SAL_CK CHECK(SALARY < 10001);
2.4.6 约束命名规范
约束名称建议自己定义一套命名规则,否则使用系统生成的约束名,很难能把它和对 应的表、字段联系起来。
| 类型 | 命名 |
|---|---|
| 非空约束 | tabname_colname_nn |
| 唯一约束 | tabname_colname_uk |
| 主键约束 | tabname_pk |
| 外键约束 | tabname_colname_fk |
| 条件约束 | tabname_colname_ck |
| 默认约束 | tabname_colname_df |
如果约束名称超过 32 位长度,建议应该缩写表名,而不应用 tabname_colname_nn
不过具体视情况而定
2.5 数据字典和动态性能视图
2.5.1 数据字典
Oracle 的数据库组织方式中所有数据库的表信息,类信息等元信息也是存放在一个对 用户不可见的数据表中,这里称之为元表。Oracle 定义了一系列示例图来表示数据字 典,大体上有如下几种
| 前缀 | 用户可见性 | 内容 |
|---|---|---|
dba_* |
数据库管理员 | 所有的对象 |
all_* |
所有用户 | 当前用户可访问的对象 |
user_* |
所有用户 | 当前用户的对象 |
例如: user_tab_comments 表中存放着用户表的注释, dba_tab_comments 表中
则存放在管理员的所有表注释。
2.5.2 数据字典的使用
表列属性,可以查看表中每列的名字,数据类型,长度等信息
SELECT C.TABLE_NAME, C.COLUMN_NAME, C.DATA_TYPE, C.DATA_LENGTH, C.NULLABLE FROM USER_TAB_COLUMNS C ORDER BY C.TABLE_NAME;
唯一性约束,获取列的约束名称
SELECT C.OWNER, C.CONSTRAINT_NAME, C.TABLE_NAME, C.COLUMN_NAME, C.POSITION FROM USER_CONS_COLUMNS C ORDER BY C.TABLE_NAME;
获取列的约束类型
SELECT C.CONSTRAINT_NAME, C.CONSTRAINT_TYPE, C.STATUS FROM USER_CONSTRAINTS C WHERE UPPER(C.CONSTRAINT_TYPE) IN ('U', 'P') ORDER BY C.CONSTRAINT_NAME;
获取数据库中的一些注释信息
-- 获取所有表注释 SELECT C.TABLE_NAME, C.TABLE_TYPE, C.COMMENTS FROM USER_TAB_COMMENTS C ORDER BY C.TABLE_NAME; -- 获取所有表的对应列的注释 SELECT C.TABLE_NAME, C.COLUMN_NAME, C.COMMENTS FROM USER_COL_COMMENTS C ORDER BY C.TABLE_NAME;
2.5.3 动态性能视图
Oracle 提供了一下可以查看当前数据库性能的视图,这些视图的统一前缀为 v$*
v$instance实例视图v$bgprocess后台进程视图v$sqlSQL 执行记录视图v$datafileData files 的视图
查看所有系统性能视图名称
SELECT D.TABLE_NAME FROM DICTIONARY D WHERE UPPER(D.TABLE_NAME) LIKE 'V$%' ORDER BY D.TABLE_NAME;
查看数据库对象
-- 所有 DBA_ 开头的数据库对象信息 SELECT O.OWNER, O.OBJECT_NAME, O.OBJECT_TYPE FROM DBA_OBJECTS O ORDER BY O.OWNER, O.OBJECT_NAME; -- 所有 ALL_ 开头的数据库对象信息 SELECT O.OWNER, O.OBJECT_NAME, O.OBJECT_TYPE FROM ALL_OBJECTS O ORDER BY O.OWNER, O.OBJECT_NAME; -- 所有 USER_ 开头的数据库对象信息SELECT O.OBJECT_NAME, O.OBJECT_TYPE FROM USER_OBJECTS O ORDER BY O.OBJECT_NAME;
所有用户对象的多少和用户的角色相关,见如下的例子
SQL> set role all; Role set. SQL> select count(1) from all_objects; COUNT(1) ---------- 18474 SQL> set role none; Role set. SQL> select count(1) from all_objects; COUNT(1) ---------- 15267
3 数据存取
3.1 SQL 语句的分类
- DDL (Data Definition Language) 是数据定义语言
- DML (Data Manipulation Language) 是数据操作语言
- TCS (Transaction Control Statements) 是事务控制语句
3.2 DDL 语句
DDL 语句包括如下几类:
- 创建,修改和删除数据库对象的语句,大多数以
create,alter和drop开头 - 删除数据库对象中的所有的数据的语句,
truncate - 授权和取消权限的语句,
grant,revoke - 修改审计相关选项,
audit,noaudit - 添加注释到数据字典的语句,
comment
执行 DDL 语句相当于隐式提交事务, 常见的 DDL 语句如下:
CREATE TABLE PLANTS ( PLANT_ID NUMBER PRIMARY KEY, COMMON_NAME VARCHAR2(15) ); ALTER TABLE PLANTS ADD (LATIN_NAME VARCHAR2(40)); GRANT SELECT ON PLANTS TO SCOTT; REVOKE SELECT ON PLANTS FROM SCOTT; DROP TABLE PLANTS;
3.3 DML 语句
DML 语句操作数据库已经存在的数据,主要有以下几类:
- 获取数据库表和视图中的数据
select - 将数据或子查询的数据插入表
insert - 修改表的数据值
update - 更新或插入列到表或视图中
merge - 删除表或视图中的列
delete - 查看执行计划
explain plan - 锁表或锁视图
lock table
SELECT * FROM EMPLOYEES; INSERT INTO EMPLOYEES (EMPLOYEE_ID, LAST_NAME, EMAIL, JOB_ID, HIRE_DATE, SALARY) VALUES (1234, 'MASCIS', 'JMASCIS', 'IT_PROG', '14-FEB-2011', 9000); UPDATE EMPLOYEES SET SALARY=9100 WHERE EMPLOYEE_ID=1234; DELETE FROM EMPLOYEES WHERE EMPLOYEE_ID=1234;
3.3.1 查询语句
Select 查询语句是最常见的 DML,并且大多数和数据库打交道的工作就是查数据,下面 是一个查询的例子
SELECT EMAIL, DEPARTMENT_NAME FROM EMPLOYEES JOIN DEPARTMENTS ON EMPLOYEES.DEPARTMENT_ID = DEPARTMENTS.DEPARTMENT_ID WHERE EMPLOYEE_ID IN (100,103) ORDER BY EMAIL;
Join 类型有以下几种:
inner join内连接,默认连接方法,只有满足条件的才返回outer join外链接,外链接包括left outer join和right outer join, 外链接将一段的数据全量返回,如果不满足条件的补 NULL- 笛卡尔积,对待处理表的所有排列,即笛卡尔积进行返回
-- 左连接,如果有些员工没有部门 ID 对应的部门名称返回 NULL SELECT EMAIL, DEPARTMENT_NAME FROM EMPLOYEES LEFT JOIN DEPARTMENTS ON EMPLOYEES.DEPARTMENT_ID = DEPARTMENTS.DEPARTMENT_ID WHERE EMPLOYEE_ID in (100,103) ORDER BY EMAIL; -- 笛卡尔积,返回所有员工和部门的排列 SELECT EMPLOYEE_NAME, DEPARTMENT_NAME FROM EMPLOYEES, DEPARTMENTS ORDER BY EMPLOYEE_NAME, DEPARTMENT_NAME;
3.3.2 子查询和隐式查询
如果一个查询包含在另外一个查询语句中,则该语句被称为子查询 (subquery)
SELECT FIRST_NAME, LAST_NAME FROM EMPLOYEES WHERE DEPARTMENT_ID IN ( SELECT DEPARTMENT_ID -- 子查询 FROM DEPARTMENTS WHERE LOCATION_ID = 1800 );
隐式查询指一些语句没有使用 select 关键字,但实际上执行了查询结果集
UPDATE EMPLOYEES SET SALARY = SALARY * 1.1 WHERE LAST_NAME = 'Baer';
3.4 TCS 语句
set transaction name 'Update salaries'; savepoint before_salary_update; update employees set salary = 9100 where employee_id = 1234; -- DML -- 这里回退了,上一句 DML 实际不会被提交 rollback to savepoint before_salary_update; -- 这里提交了,上一句 DML 才会生效 update employees set salary = 9200 where employee_id = 1234; -- DML commit comment 'Updated salaries';
3.5 SQL 优化与解析
3.5.1 优化器
Oracle 在执行 DML 语句时,不是直接将语句解析出来执行,而是生成相应的执行计划 (Execution Plan),根据生成的执行计划后,优化器就可以获取语句涉及到的执行信息, 包括 query 条件,对应的存取路径 (Access Path),优化器最后生成一个高效的查询 计划 (Query Plan),最后执行查询
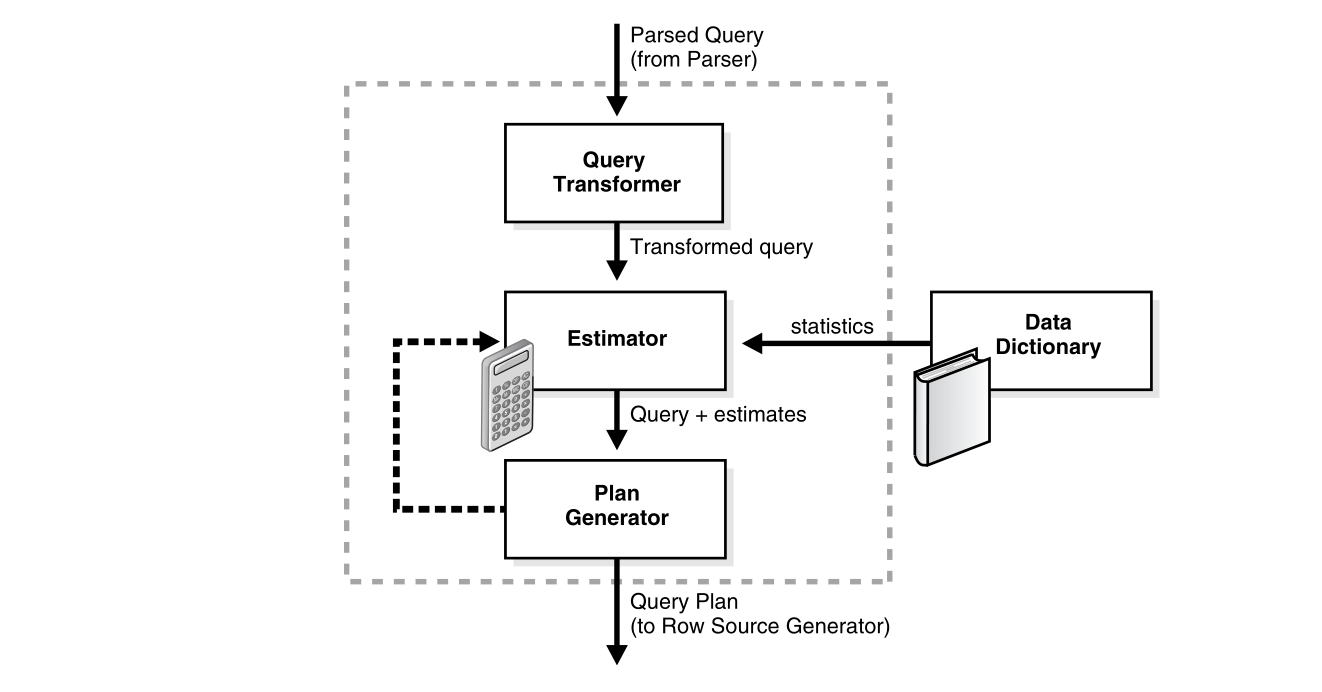
下面是一个查看语句执行计划的示例
SQL> set autotrace on SQL> select count(1) from t_department; COUNT(1) ---------- 26 Execution Plan ---------------------------------------------------------- Plan hash value: 3597430146 ---------------------------------------------------------------------------- | Id | Operation | Name | Rows | Cost (%CPU)| Time | ---------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 1 (0)| 00:00:01 | | 1 | SORT AGGREGATE | | 1 | | | | 2 | INDEX FULL SCAN| T_DEPARTMENT_PK | 24 | 1 (0)| 00:00:01 | ---------------------------------------------------------------------------- Statistics ---------------------------------------------------------- 0 recursive calls 0 db block gets 1 consistent gets 0 physical reads 0 redo size 526 bytes sent via SQL*Net to client 524 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed
| autotrace | Note |
|---|---|
| on | Display both explain and statistics |
| on explain | Display explain only |
| on statistics | Display statistics only |
| traceonly | Disable print result set |
| off | Disable auto trace |
3.5.2 SQL 处理机制
DDL 语句用来创建数据库中的对象, DML 语句用来获取数据库中的数据。这些 SQL 语句在执行前都要进行处理,处理时,Oracle 创建一个 parse call 来准备执行,这 个 parse call 打开或创建一个 cursor,cursor 的作用是处理特定会话的私有 SQL 区域,以上的处理都是需要消耗 PGA。解析流程如下图所示
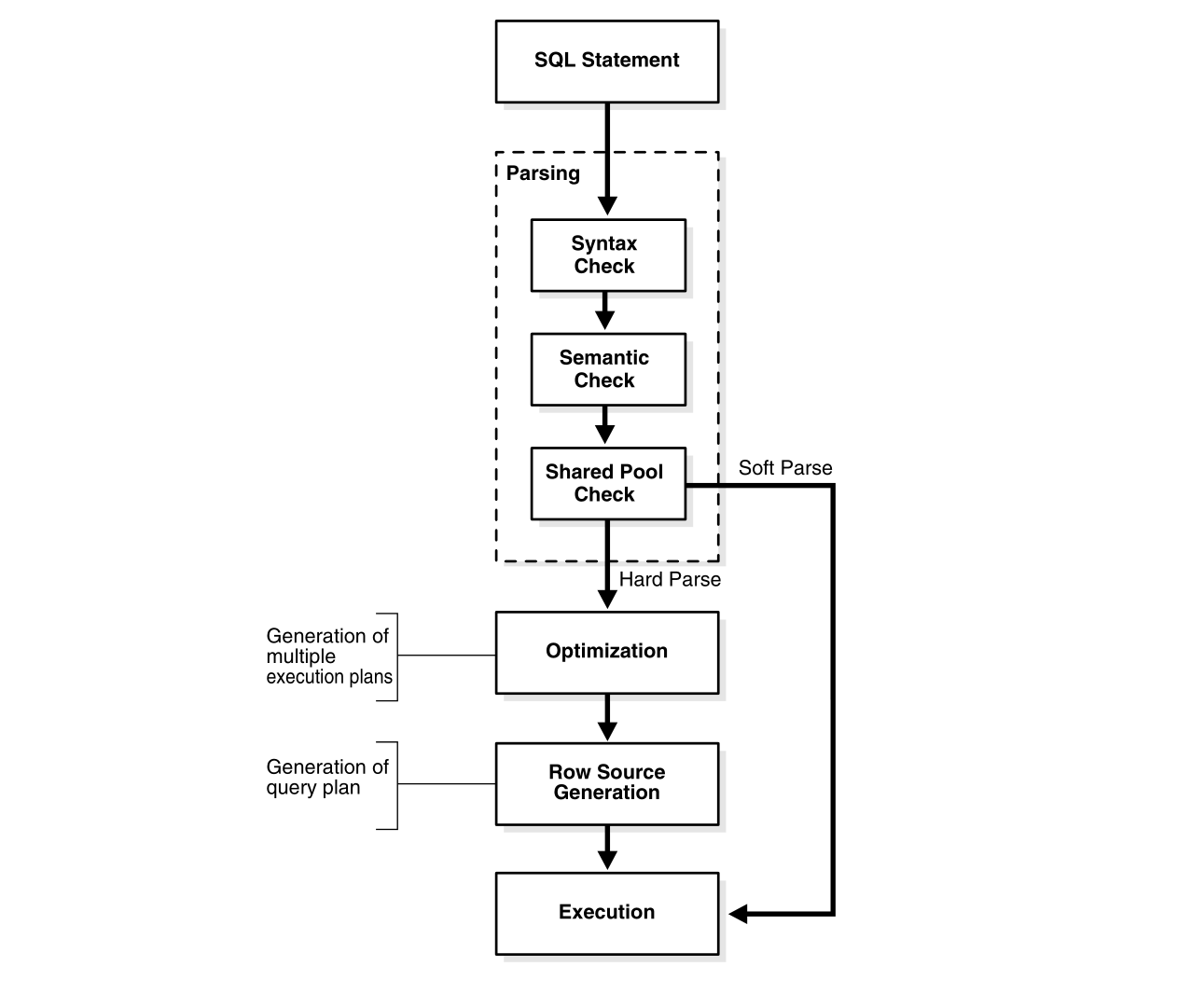
根据上面的图,解析大体上包含下面几个步骤:
- 词法检查
- 语法检查
- Shared Pool 检查
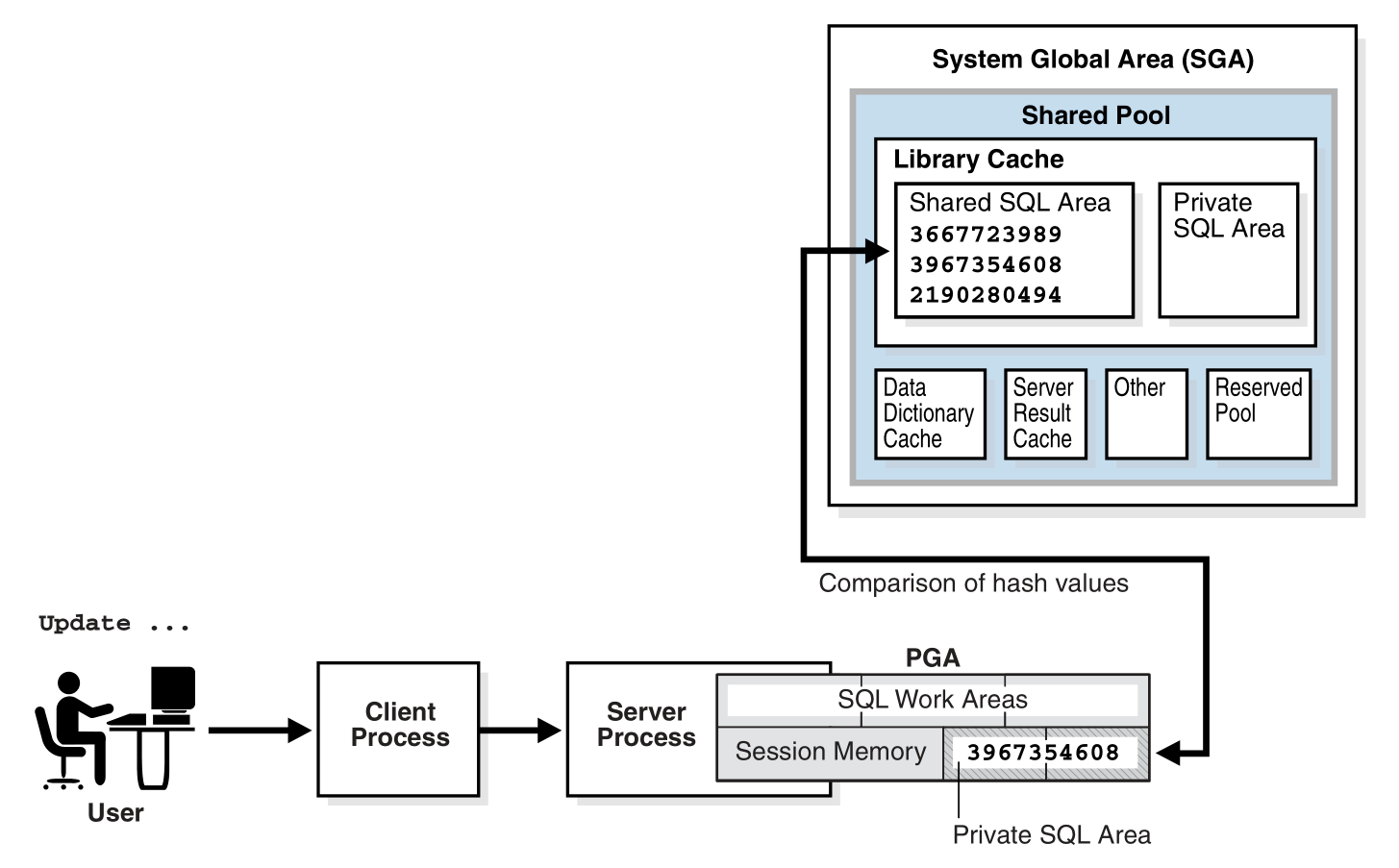
已经执行过的 SQL 语句会放到 Library Cache 中缓存。在解析 SQL 语句前,Oracle 会通过哈希值在 Library Cache 中查找缓存的 SQL 语句,如果没有命中,则执行硬解 析,否则执行软解析
查看 SQL 的哈希值就是, v$sql 视图中的 sql_id, 下面是一个查看哈希值的例子
SQL> select sql_id, sql_text from v$sql where sql_text like '%hashtag%'; SQL_ID SQL_TEXT ------------- ---------------------------------------------------------------- d6a6j07p0jfu3 select sql_id, sql_text from v$sql where sql_text like '%hashtag%' SQL> select /* hashtag */ sysdate from dual; SYSDATE ------------------- 2020-02-25 03:42:29 SQL> select sql_id, sql_text from v$sql where sql_text like '%hashtag%'; SQL_ID SQL_TEXT ------------- ----------------------------------------------------------------- d6a6j07p0jfu3 select sql_id, sql_text from v$sql where sql_text like '%hashtag%' gadbmhc20xhx8 select /* hashtag */ sysdate from dual -- 这里发生了硬解析 SQL> select /* hashtag */ sysdate from dual; SYSDATE ------------------- 2020-02-25 03:51:54 SQL> select sql_id, sql_text from v$sql where sql_text like '%hashtag%'; SQL_ID SQL_TEXT ------------- ----------------------------------------------------------------- d6a6j07p0jfu3 select sql_id, sql_text from v$sql where sql_text like '%hashtag%' gadbmhc20xhx8 select /* hashtag */ sysdate from dual -- library cache 命中,这里发生了软解析 SQL> select /* hashtag new */ sysdate from dual; SYSDATE ------------------- 2020-02-25 04:00:29 SQL> select sql_id, sql_text from v$sql where sql_text like '%hashtag%'; SQL_ID SQL_TEXT ------------- ----------------------------------------------------------------- d3k0qy7gmnz75 select /* hashtag new */ sysdate from dual d6a6j07p0jfu3 select sql_id, sql_text from v$sql where sql_text like '%hashtag%' gadbmhc20xhx8 select /* hashtag */ sysdate from dual -- 注意,SQL 的哈希值是根据字符串计算的 -- 如果 SQL 的语义一样,但字符串不一样导致哈希值不一样也会发生硬解析
3.6 PL/SQL
PL/SQL 是直接存在 Oracle 数据库内存中的,减少了获取和解析 SQL 计算的资源消耗, 可以有效地提高执行效率
3.6.1 变量
变量类型
- 普通变量(char, varchar2, date, number, boolean, long)
- 特殊变量(引用型变量,记录型变量)
varname varchar2(20);
变量赋值
- 直接赋值
:= - 语句赋值,使用
select ... into ...
declare v_name varchar(20) := ''; -- 初始化赋值 v_sal number; v_addr varchar(200); begin -- 直接赋值 v_sal := 2383; -- 语句赋值 select '北京市朝阳区' into v_addr from dual; dbms_output.put_line('姓名: ' || v_name || ', 薪水: ' || v_sal || ', 地址 c: ' || v_addr); end;
3.6.2 子程序 Subprogram
子程序包括: procedure 和 function 两类,其中 function 有返回值, procedure 没 有返回值
create procedure hire_employees ( p_last_name varchar2, p_job_id varchar2, p_manager_id number, p_hire_date date, p_salary number, p_commission_pct number, p_department_id number ) is begin -- ... insert into employees (employee_id, last_name, job_id, manager_id, hire_date, salary, commission_pct, department_id) values (emp_sequence.nextval, p_last_name, p_job_id, p_manager_id, p_hire_date, p_salary, p_commission_pct, p_department_id); -- ... end;
执行子程序的方法如下:
execute hire_employees ('TSMITH', 'CLERK', 1037, sysdate, 500, null, 20);
3.6.3 包 Package
PL/SQL 的包和 Java 的很相似,提供封装性
create package employees_management as function hire_employees (last_name varchar2, job_id varchar2, manager_id number, salary number, commission_pct number, department_id number) return number; -- 定义函数 procedure fire_employees(employee_id number); -- 定义过程 procedure salary_raise(employee_id number, salary_incr number); -- ... no_sal exception; end employees_management; -- 包尾的名称需要和前面一致
调用包中函数的方法
execute employees_management.hire_employees ('tsmith', 'clerk', 1037, sysdate, 500, null, 20);
3.6.4 匿名块 Anonymous Block
匿名块是没有名字的过程,使用 / 来执行
declare v_lname varchar2(25); begin select last_name into v_lname from employees where employee_id = 101; -- sqlplus 中默认输出是关闭的,可以使用下面方法开启选项 -- set serveroutput on dbms_output.put_line('Employee last name is ' || v_lname); end;
3.7 触发器 Trigger
触发器定义了 Oracle 表操作的一些自动使用的行为,和 Hook 机制很像
3.7.1 创建触发器
create trigger trigger_name triggering_statement [trigger_restriction] begin triggered_action; end;
3.7.2 触发器使用
创建示例表
create table orders ( order_id number primary key, /* other attributes */ line_items_count number default 0 ); create table lineitems ( order_id references orders, seq_no number, /* other attributes */ constraint lineitems primary key(order_id, seq_no) );
创建一个触发器,自动适配上述两张表对应操作的行为
create or replace trigger lineitems_trigger after insert or update or delete on lineitems for each row begin if (inserting or updating) then update orders set line_items_count = nvl(line_items_count,0)+1 where order_id = :new.order_id; end if; if (deleting or updating) then update orders set line_items_count = nvl(line_items_count,0)-1 where order_id = :old.order_id; end if; end; /
3.8 Java
Oracle 支持服务器端使用 Java 编程的存储过程 (Java stored procedure),但是目前 很少使用,因为与 Oracle 数据库紧耦合,一般还是使用 JDBC 连接数据库来操作, JDBC 主要分以下几种连接方式:
- OCI (Oracle Call Interface) 包含了 Oracle 内置的代码,Java 代码等一般不能直 接使用 Java 连
- Thin 纯 Java 实现的数据库连接库
4 事务管理
4.1 事务隔离级别
对于并发读数据会出现以下 3 种情况
- Dirty Read 事务 Tx1 更新了一行记录,还未提交所做的修改,这个 Tx2 读取了 更新后的数据,然后 Tx1 执行回滚操作,取消刚才的修改,所以 Tx2 所读取的行就 无效,也就是脏数据
- Nonrepeatable Read 事务 Tx1 读取一行记录,紧接着事务 Tx2 修改了 Tx1 刚刚 读取的记录并 commit,然后 Tx1 再次查询,发现与第一次读取的记录不同,这称为 不可重复读
- Phantom Read 事务 Tx1 读取一条指定 where 条件的语句,返回结果集。此时事 务 Tx2 插入一行新记录并 commit,恰好满足 Tx1 的 where 条件。然后 Tx1 使用 相同的条件再次查询,结果集中可以看到 Tx2 插入的记录,这条新纪录就是幻想
标准 SQL 针对上述读问题设计 4 中隔离级别:
| Dirty Read | Nonrepeatable Read | Phantom Read | |
|---|---|---|---|
| Read Uncommitted | Possible | Possible | Possible |
| Read Committed | Not Possible | Possible | Possible |
| Repeatable Read | Not Possible | Not Possible | Possible |
| Serializable | Not Possible | Not Possible | Not Possible |
Oracle 事务包含以下三个隔离级别
- Read Committed 是 Oracle 默认的事务隔离级别,事务内只能读到事务开始时间 点的数据 ,事务执行过程中改变的数据对当前事务不可见
- Serializable 事务内不仅读到事务开始时间点的数据,事务执行中的修改也能读
到,所以这种事务隔离级别可以读到最新数据,相当于串行操作,所以并发性不是很
好,该类事务常用于以下几种场合
- 数据规模大但事务时间短并且更新行数少
- 两个事务竞争方式修改的行,并且这些行是不相关的
- 执行时间比较长,但是是只读的事务
- Read-Only 只读级别的事务
事务的隔离级别可以使用以下的 SQL 来设置
set transaction isolation level read committed; -- 提交可读 set transaction isolation level serializable; -- Serializable 级别 set transaction isolation level read uncommitted; -- 标准 SQL 支持,Oracle 不支持
4.2 数据库锁机制
数据库锁是模式包含两种: 共享 (Share) 和 互斥 (Exclusive)。如果两个用户在 同时等待的资源同时被对方锁住了就会出现 死锁 (Deak lock)
4.2.1 DML 锁
DML 锁在 Oracle 中被称为数据所,主要分成以下两类
- TX lock 即行锁 (Row Lock) 在 Oracle 表中锁住表的一行
- TM lock 即表锁 (Table Lock) 在 Oracle 中对表操作进行锁
- RS (Row Share)
- RX (Row Exclusive Table)
- S (Share Table)
- SRX (Share Row Exclusive Table)
- X (Exclusive Table)
TM 锁可以的锁模式见下表
| Share / eXclusive | Table | Row |
|---|---|---|
| RS | S | |
| RX | X | |
| S | S | |
| SRX | X | S |
| X | X |
-- 请求 TX 的语句 select /* ... */ for update; insert /* ... */ ; update /* ... */ ; delete /* ... */ ; merge /* ...*/ ;
-- 请求 TM 的语句 lock table /* ... */ ; select /* ... */ for update; insert /* ... */ ; update /* ... */ ; delete /* ... */ ; merge /* ... */ ;
4.2.2 DDL 锁
DDL 锁主要是保护数据字典,用户一般不会直接获取 DDL 锁,但是在创建数据库对象 是会隐式获取改锁,例如:创建存储过程是会获取 DDL 锁
4.2.3 系统锁
- Latch 是 Oracle 数据库中的低级别的系统锁,用来保护数据库对象,数据结构, 对象和文件等。数据库内部的后台进程,共享池,写进程都是使用 Latch 来完成同 步的。
- Mutex 是另一个低级别的系统锁,与 Latch 相似,不同之处是 Latch 通常保护一 组数据库对象,而 Mutex 保护单个数据库对象
- Internal Locks 系统还有其它的锁
- Dictionary cache locks
- File and log management locks
- Tablespace and undo segment locks
4.3 事务概述
在数据库中事务是工作的逻辑单元,一个事务是由一个或多个完成一组的相关行为的 SQL 语句组成,通过事务机制确保这一组 SQL 语句所作的操作要么完全成功执行,完成 整个工作单元操作,要么一点也不执行。
事务的四个特性 ACID 见如下描述
- 原子性 (Atomicity) 事务中 SQL 语句不可分割,要么都做,要么都不做
- 一致性 (Consistency) 指事务操作前后,数据库中数据是一致的,数据满足业务 规则约束 (例如账户金额的转出和转入),与原子性对应。
- 隔离性 (Isolation) 多个并发事务可以独立运行,而不能相互干扰,一个事务修 改数据未提交前,其他事务看不到它所做的更改。
- 持久性 (Durability) 事务提交后,数据的修改是永久的
4.4 事务开始和结束
事务开始 在 Oracle 数据库中,没有提供开始事务处理语句,所有的事务都是隐式开 始的,也就是说在 Oracle 中,用户不可以显示使用命令来开始一个事务。Oracle 任务 第一条修改数据库的语句, 或者一些要求事务处理的场合都是事务的隐式开始。
事务结束 主要发生在以下几种情况下:
- 执行 DDL 语句时,系统自动执行
commit语句,相当于隐式提交事务 - 显示执行
commit和rollback - 退出/断开数据库的连接自动执行
commit语句 - 进程意外终止,事务自动
rollback - 事务
commit时会生成一个唯一的系统变化号保存到事务表,这个系统变化号被称 为 SCN (System Check Number) 号
开始的事务都可以在 v$transaction 视图中看到
SQL> select xid from v$transaction; XID ---------------- 02001700A8010000
4.5 事务属性和约束模式
- 事务属性 主要包括:
- 指定事务的隔离级别,默认为
read committed - 规定回滚事务所使用的存储空间,存储空间的设置很少使用
- 命名事务,即事务的名称。对于命名事务也非常简单,只有在分布式事务处理中才 会体现出命名事务的用途
- 指定事务的隔离级别,默认为
- 约束模式 在事务中修改数据时,数据库中的约束立即应用于数据,还是将约束推迟 到当前事务结束后应用。
-- 设置事物属性 只对当前事务有效,事务终止,事务当前的设置将会失效。 set transaction <options>; -- 设置事物的约束模式 set constrains <options>; -- 在事务中建立一个存储的点.当事务处理发生异常而回滚事务时, -- 可指定事务回滚到某存储点.然后从该存储点重新执行。 savepoint spname; -- 删除存储点 release savepoint spname; -- 回滚事务 rollback; rollback to savepoint spname; -- 提交事务 commit;
5 数据库底层结构
5.1 物理存储结构
在使用 create database 建立数据库后,数据库会创建数据文件、控制文件和重做日
志这三个文件。在实际生产环境,我们一般使用 dbca 图形化工具来创建数据库,而
不直接使用 SQL 语句来创建
5.1.1 数据文件 Data Files
Oracle 数据库中的数据文件包含永久数据文件和临时数据文件
- 数据库中的永久存储对象,例如表,不会放在临时数据文件中
- 临时数据文件没有
NOLOGGING模式 - 临时数据文件不再设置成只读模式
临时数据文件信息存放在
dba_temp_files和v$tempfile视图中,而永久数 据文件信息存放在dba_data_files和v$datafile视图中-- 查看临时数据文件 SELECT T.CREATION_TIME AS "Creation Time", ROUND(T.BYTES / 1024 / 1024, 2) AS "Size (M)", SUBSTR(T.NAME, 1, 60) AS "File Name" FROM V$TEMPFILE T ORDER BY T.NAME; -- 查看永久数据文件 SELECT T.CREATION_TIME AS "Creation Time", ROUND(T.BYTES / 1024 / 1024, 2) AS "Size (M)", SUBSTR(T.NAME, 1, 60) AS "File Name" FROM V$DATAFILE T ORDER BY T.NAME;
数据文件的状态分为 ONLINE 和 OFFLINE,备份文件、重命名文件等操作会使得数 据文件离线
-- 查看离线的数据文件 SELECT T.CREATION_TIME AS "Creation Time", ROUND(T.BYTES / 1024 / 1024, 2) AS "Size (M)", SUBSTR(T.NAME, 1, 60) AS "File Name" FROM V$TEMPFILE T WHERE LOWER(T.STATUS) = 'offline' UNION SELECT T.CREATION_TIME AS "Creation Time", ROUND(T.BYTES / 1024 / 1024, 2) AS "Size (M)", SUBSTR(T.NAME, 1, 60) AS "File Name" FROM V$DATAFILE T WHERE LOWER(T.STATUS) = 'offline';
5.1.2 控制文件 Control Files
控制文件是一个很小的二进制记录文件,数据库启动是通过控制文件查找数据库的数据 文件的位置,大小以及其他的信息。控制文件中包含数据关闭或宕机时的 SCN 号,数 据库进行实例恢复是需要控制文件提供必要的信息。
5.1.3 重做日志 Redo Log Files
重做日志记录着数据库的操作,如果数据库发送宕机,可以通过控制文件和重做日志将 数据从一个比较老的检查点 (Checkpoint) 上恢复回来。
重做日志包含:在线重做日志和归档重做日志。重做日志是 循环 使用的,过了检查
点的操作日志会被重用。归档重做日志和数据的 ARCHIVELOG 模式有关系,开启归档
模式的话,数据库会按照一定规则生成归档重做日志,用于备份和恢复。
重做日志记录了以下信息
- SCN 号,时间戳
- 事务 ID,记录重做日志完成的事务
- SCN 时间点,事务 ID 对应的事务是否提交的信息
- 修改的类型
- 修改段的名称和类型
5.2 逻辑存储结构
数据库的逻辑存储结构和物理储存有点区别,具体见下图
5.2.1 块 Block
块是数据库中最小的数据管理单元,可以通过下面启动参数指定大小
show parameter db_block_size;
注意:数据库块大小一但启动后不要轻易修改,11g 中默认的块大小为 8K。在创建新 的表空间是可以通过参数指定表空间的块大小,一旦表空间创建,块大小不要修改
数据库表的数据是存在块上的,通过列的相对位置来寻找到 Row Data,然后在 Row Data 中查找 Column Data
- Oracle 会将 LONG 类型的数据放在 Row Data 的最后面。
Oracle 的
rowid伪列满足下面的结构SQL> select rowid from employees where employee_id = 100; ROWID ------------------ AAAPecAAFAAAABSAAA

Oracle 运行手工管理表分配块的大小,一旦指定 pctfree 参数,Oracle 在创建块
是要是的为分配的块不低于 pctfree 的值
-- Percentage of Free Space in Data Blocks create table test_table (n number) pctfree 20;
5.2.2 区 Extent
区是数据库管理数据的一个单位,主要记住一个区只能放在一个 Datafile 中,而段是 可以跨 Datafile 的,所以段在扩展时,新扩展的分区可能会放在不同的 Datafile 中。
区的管理可以是手动的,也可以是自动的。如果需要统一管理在创建表空间是指定扩展 区大小为 1M
5.2.3 段 Segment
Oracle 的段一般对应与一张表
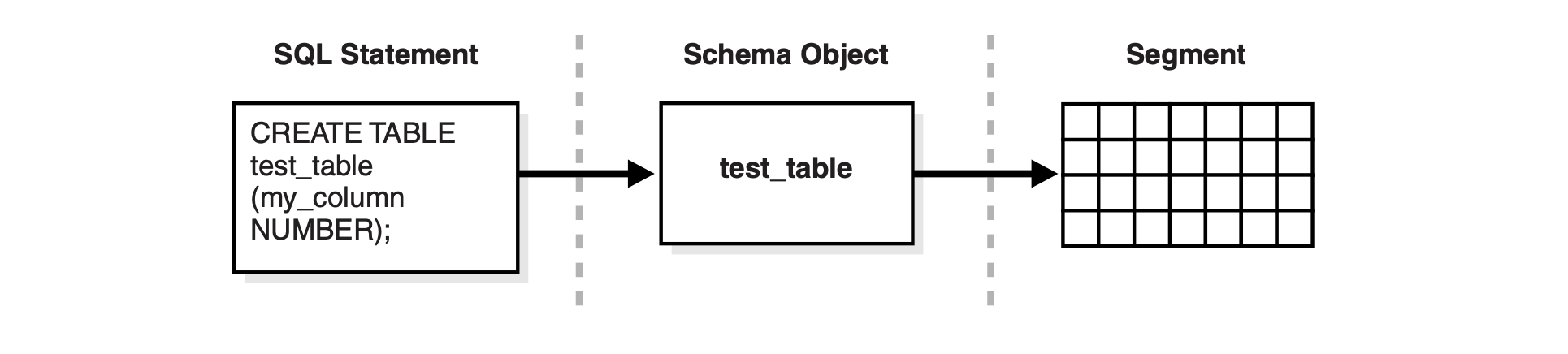
对于包含主键、索引和 Lob 字段的表,可能会包含多个段
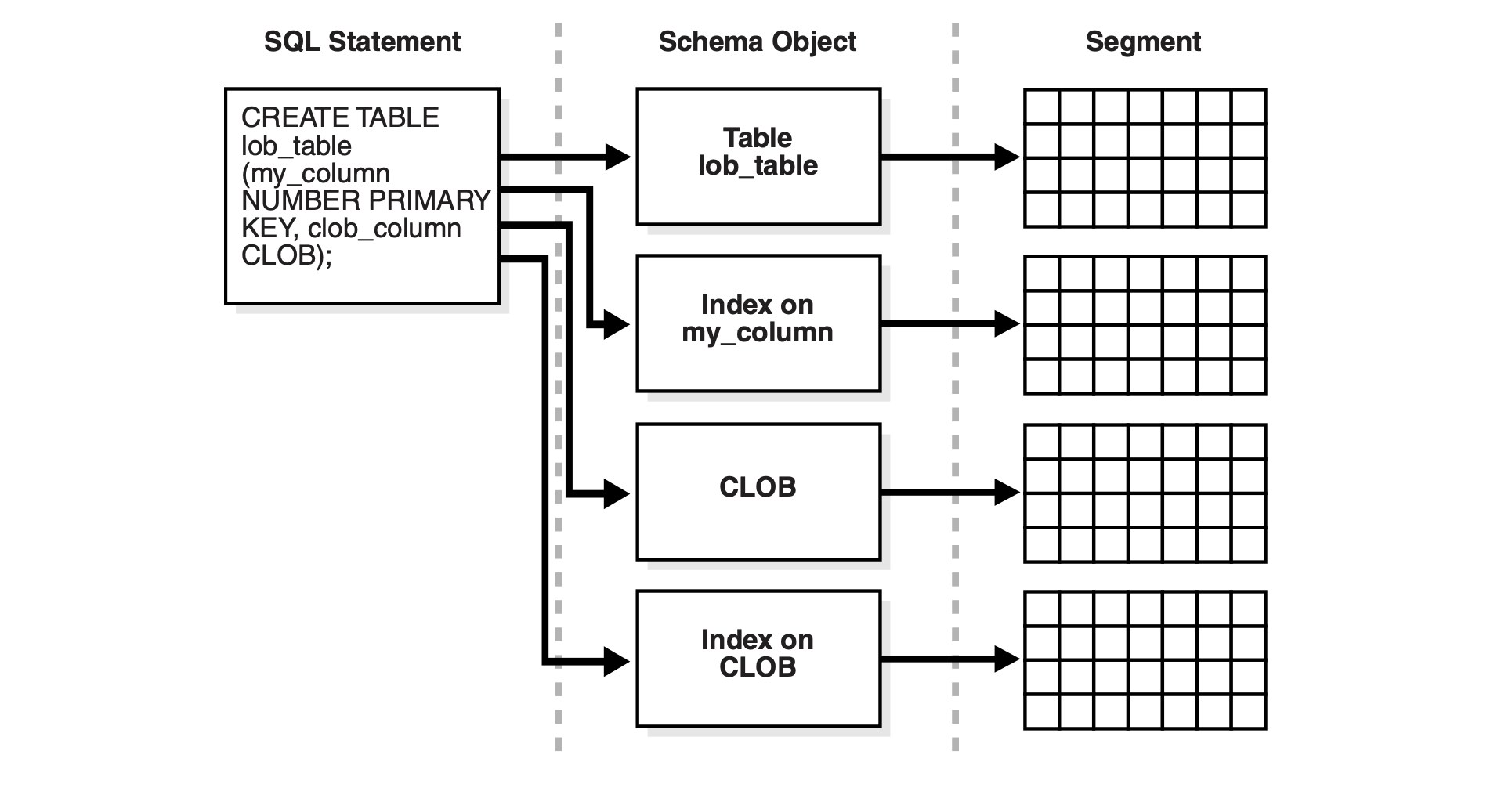
段主要有以下几个点:
- Oracle 11g 使用延迟段创建 (Deferred Segment Creation) 的策略,该策略是数 据库在建表时不创建对象,当向表里插入数据是才开始创建对象
- Oracle 为临时表分配临时段
- Undo 段是采用循环回收机制
- 段存在高水位线 HWM (High water mark),高水位线会对全表扫描效率产生影响
5.2.4 表空间 Tablespace
表空间是管理数据库的逻辑单元
- 一个表空间可以对应与多个数据文件
- SYSTEM 和 SYSAUX 是系统的表空间,Oracle 启动时必须要有这两个表空间
- Undo 表空间是循环管理的,对于循环空间的保鲜时间通过
undo_retention启动 参数配置 - Oracle 建立用户前必须先建立表空间,因为建立用户是一般会指定该用户的默认表 空间和默认临时表空间
-- 查看表空间和数据文件的对应关系 COLUMN "Tablespace" FORMAT A20; COLUMN "Datafile" FORMAT A60; SELECT A.TABLESPACE_NAME AS "Tablespace", A.FILE_NAME AS "Datafile" FROM DBA_DATA_FILES A ORDER BY A.TABLESPACE_NAME, A.FILE_NAME;
-- 看表空间剩余的容量 COLUMN "Tablespace" FORMAT A20; SELECT A.TABLESPACE_NAME AS "Tablespace", SUM(BLOCKS) AS "Blocks", ROUND(SUM(BYTES) / 1024 / 1024, 2) AS "Free (M)" FROM DBA_FREE_SPACE A GROUP BY A.TABLESPACE_NAME ORDER BY A.TABLESPACE_NAME;
-- 查看表空间使用量 COLUMN "Tablespace" FORMAT A20; SELECT SUBSTR(A.TABLESPACE_NAME, 1, 20) AS "Tablespace", ROUND(A.BYTES / 1024 / 1024, 2) AS "Size (M)", DECODE(B.USED_BYTES, NULL, 0, ROUND(B.USED_BYTES / 1024 / 1024, 2)) AS "Current (M)", DECODE(C.FREE_BYTES, NULL, 0, ROUND(C.FREE_BYTES / 1024 / 1024, 2)) AS "Free (M)", DECODE(B.USED_BYTES, NULL, 0, ROUND((B.USED_BYTES / A.BYTES) * 100, 2)) AS "Used (%)" FROM DBA_DATA_FILES A, ( SELECT FILE_ID, SUM(BYTES) USED_BYTES FROM DBA_EXTENTS GROUP BY FILE_ID ) B, ( SELECT SUM(BYTES) FREE_BYTES, FILE_ID FROM DBA_FREE_SPACE GROUP BY FILE_ID ) C WHERE B.FILE_ID(+) = A.FILE_ID AND C.FILE_ID(+) = A.FILE_ID ORDER BY A.TABLESPACE_NAME, A.FILE_NAME;
-- 查看表空间对应数据文件数量 COLUMN "Tablespace" FORMAT A20; COLUMN "Datafile" FORMAT A60; SELECT A.TABLESPACE_NAME AS "Tablespace", COUNT(*) AS "Count", ROUND(SUM(BYTES) / 1024 / 1024, 2) AS "Current (M)", ROUND(SUM(MAXBYTES) / 1024 / 1024, 2) AS "Maximum (M)", ROUND(SUM(BYTES) / SUM(MAXBYTES), 2) AS "Used (%)" FROM DBA_DATA_FILES A GROUP BY A.TABLESPACE_NAME ORDER BY A.TABLESPACE_NAME;
-- 创建默认表空间 CREATE TABLESPACE PFILE1 DATAFILE '/oradata/xe/part1.dbf' SIZE 128M AUTOEXTEND OFF LOGGING ONLINE PERMANENT EXTENT MANAGEMENT LOCAL AUTOALLOCATE BLOCKSIZE 8K SEGMENT SPACE MANAGEMENT AUTO FLASHBACK ON; -- 创建临时表空间 CREATE TEMPORARY TABLESPACE TFILE1 TEMPFILE '/oradata/xe/temp1.dbf' SIZE 2048M AUTOEXTEND OFF TABLESPACE GROUP '' EXTENT MANAGEMENT LOCAL UNIFORM SIZE 1M;
5.3 数据库实例
Oracle 常见的实例包含单实例和 RAC 两种模式,他们的物理结构如下:
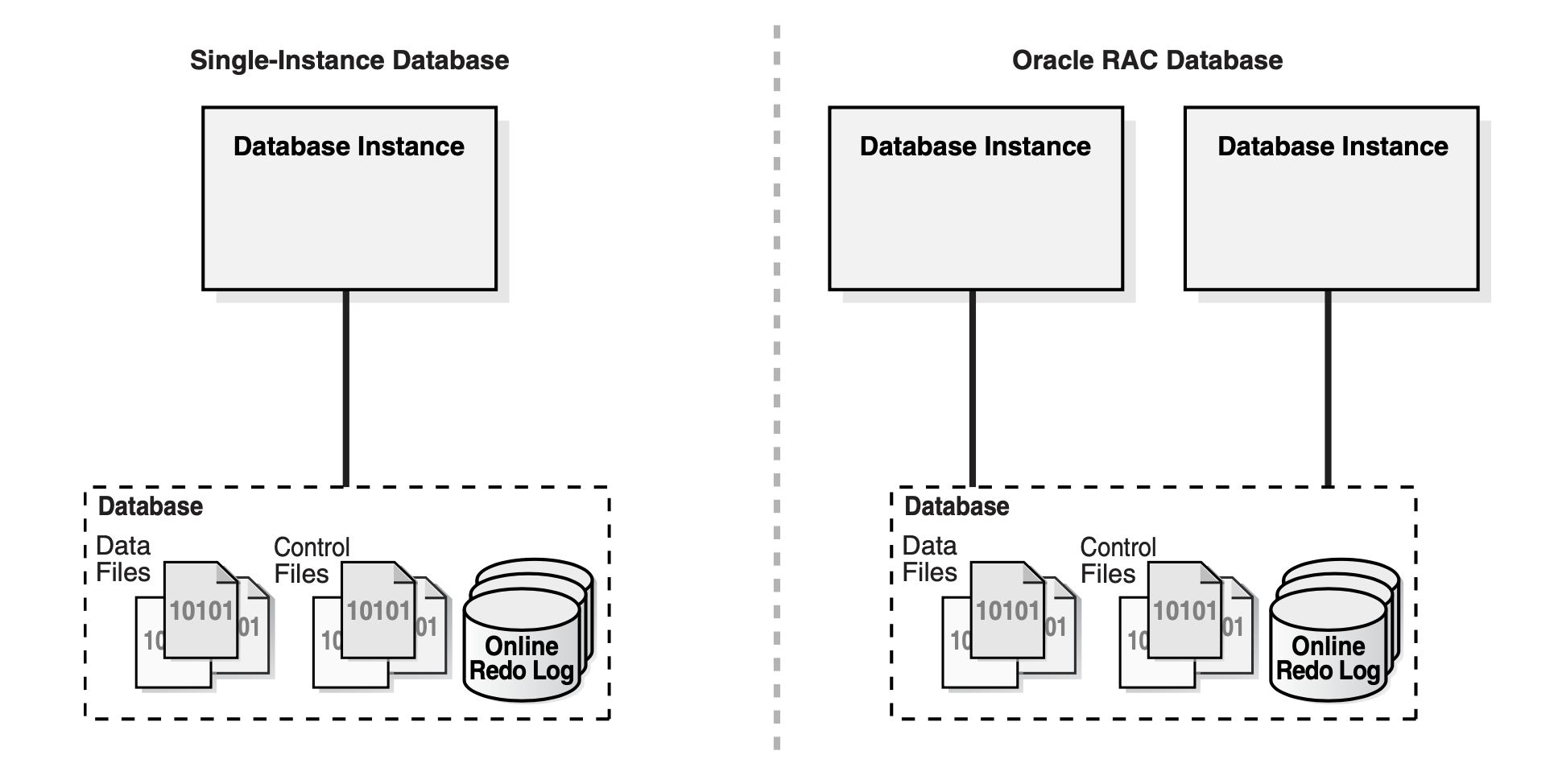
实例有以下几个知识点:
- 实例是运行在内存中,它包含多种内存结构:SGA,PGA,Buffer Cache 等
- SID 是 Oracle 数据库实例在一个主机上的唯一标识
数据库启动需要读一个二进制的配置文件 Server Parameter File,一般称为
spfile,spfile记录着数据库实例的启动参数,示例启动后spfile就没有 作用了。另外,Oracle 数据库还有一个文本的参数文件,一般称之为pfile,pfile可以和spfile相互转换。 修改数据库参数前要备份 spfile, 这样的 话如果参数修改错误可以替换文件来解决 Oracle 宕机无法启动的问题-- pfile 和 spfile 的转化 create pfile from spfile; create spfile from pfile;
实例启动分为:Shutdown -> NoMount -> Mount -> Open 四个阶段
-- 启动到 NoMount 阶段 startup nomount; -- 直接启动到 Open 阶段 startup; -- 在 NoMount 阶段将数据库开启到 Open 阶段 ALTER DATABASE OPEN;
实例关闭有以下四种模式,一般使用
shutdown immediate-- 异常关闭,和断点是一样的 shutdown abort; -- 立即关闭,不等待事务提交,不等待会话断开 shutdown immediate; -- 事务性关闭,等待事务提交,不等待会话断开 shutdown transactional; -- 正常关闭,等待事务提交,等待会话断开 shutdown normal;
- 数据库异常关闭后,示例重启可能会出现 SCN 不一致,这时 Oracle 会更加记录的 Checkpoint 以及 Redo Log 等文件来 Roll Forward 或 Roll Back,确保 SCN 号同 步。这个过程叫 实例恢复
- 数据库初始化参数分 Static 和 Dynamic 两种。
db_block_size和db_name等是静态参数,不允许用户修改。动态参数根据作用域不同有分为如下三种:scope=memory正在运行的实例生效,重启后失效scope=spfile正在运行的实例不生效,重启后失效scope=both正在运行的实例生效,重启后也生效
5.4 内存、进程和网络
5.4.1 数据库内存
数据库内存包含 SGA 和 PGA 两个主要部分,所有 SGA 和 PGA 管理在 Oracle 数据库调优中 是至关重要的。可以通过下面参数查看 Oracle 内存参数值
-- 查看 sga 和 pga 相关参数 show parameter sga; show parameter pga;
修改 SGA 和 PGA 参数的原则如下:一般物理内存 20% 用作操作系统保留,其他 80% 用于数据库,对于只作为数据库服务的机器可以加将 Oracle 的内存分配得更高。在 Oracle 数据库的内存确定后,SGA 可以分配可用内存 40% ~ 60% 之间,PGA 可以分配 可用内存 20% ~ 40% 之间
| - | parameter | range |
|---|---|---|
| OS | total_memory |
|
| OS | available_memory |
(60% ~ 90%) × total_memory |
| SGA | sga_max_size |
(60% ~ 80%) × available_memory |
| SGA | sga_target |
(60% ~ 80%) × available_memory |
| PGA | pga_aggregate_target |
(40% ~ 20%) × available_memory |
alter system set sga_max_size = 20g scope = both; alter system set sga_target = 20g scope = both; alter system set pga_aggregate_target = 8g scope = both;
修改 PGA 的自动管理方式和大小
alter system set workarea_size_policy = auto scope = both; alter system set pga_aggregate_target = 3072m scope = both;
缓存区 (Buffer Cache) 是 SGA 内部的一个重要的结构,Buffer Cache 缓存了 Oracle 数据库中数据表的 CR 块。下面的命令可以查看缓冲区的参数值,如果是 0 表 示让 Oracle 自动管理
-- 查看 Buffer Cache 参数 COLUMN "Name" FORMAT A32; COLUMN "Value" FORMAT A64; SELECT T.NAME AS "Name", T.VALUE AS "Value" FROM V$PARAMETER T WHERE T.NAME IN ('db_cache_size', 'db_keep_cache_size', 'db_recycle_cache_size');
缓冲区的命中率一般要达到 98% 以上才算正常
-- 查看缓冲区命中率 SELECT 100 * (1 - ((PHYSICAL.VALUE - DIRECT.VALUE - LOBS.VALUE) / LOGICAL.VALUE)) AS "Buffer Cache Hit Ratio (%)" FROM V$SYSSTAT PHYSICAL, V$SYSSTAT DIRECT, V$SYSSTAT LOBS, V$SYSSTAT LOGICAL WHERE PHYSICAL.NAME = 'physical reads' AND DIRECT.NAME = 'physical reads direct' AND LOBS.NAME = 'physical reads direct (lob)' AND LOGICAL.NAME = 'session logical reads';
获取推荐的缓冲区值
-- 获取推荐缓冲区值 column "Name" format a12; select a.name as "Name", a.size_for_estimate as "Adviced Size (M)", a.estd_physical_reads as "Estimed Physical Reads" from v$db_cache_advice a where block_size = '8192' and advice_status = 'ON';
游标 (Cursor) 是在 PLSQL 编程中操作数据集的句柄,相当于一个指针变量。他的形 成原因如下,由于存储过程是放在 Shared Pool 里的,当 Client Process 和 Server Process 建立连接后,待操作的结构集在 Buffer Cache 中,因此需要提供 Client Process 一个游标来寻找结果集
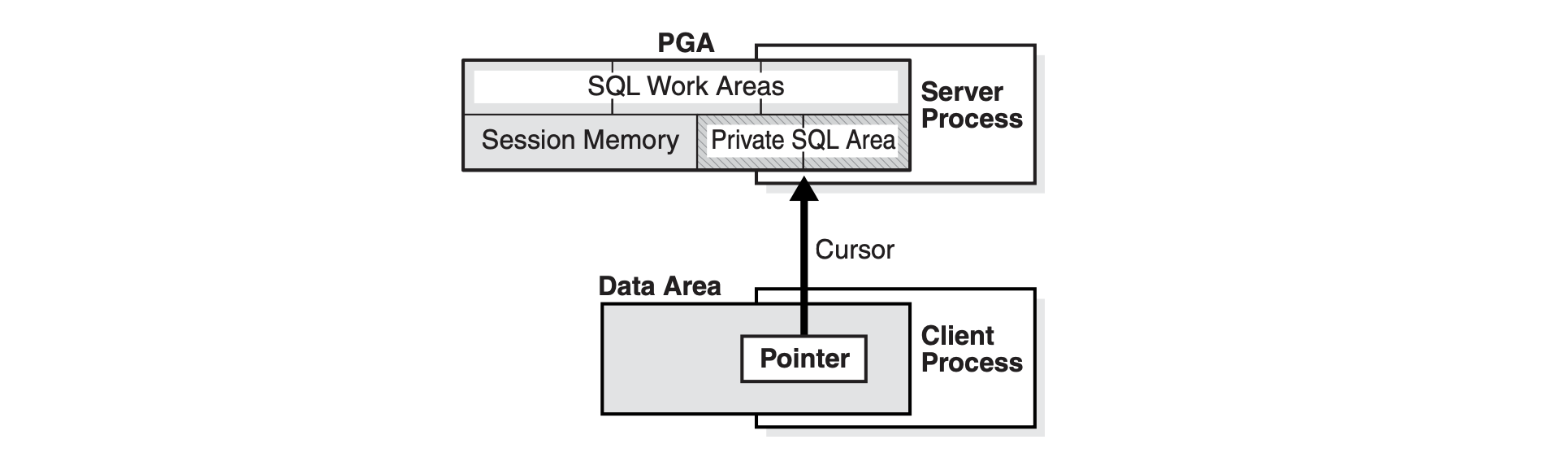
对应存储过程比较多的系统,如果代码中没有释放游标会照成 Oracle 数据库出现问题, 所以一般需要设置可使用的游标数。
alter system set open_cursors = 500 scope = both;
5.4.2 数据库进程
Oracle 的进程包括 Server Process 和 Background Process, 当客户端建立会话后, 客户端还会出现 Client Process, Background Process 主要处理 Oracle 数据库内部 的事务,下面一些常见的后台进程
- Process Monitor Process (PMON)
- System Monitor Process (SMON)
- Database Writer Process (DBWn)
- Log Writer Process (LGWR)
- Checkpoint Process (CKPT)
- Manageability Monitor Processes (MMON and MMNL)
- Recoverer Process (RECO)
对于进程参数的调整确保以下参数是正确的
-- cpu 数量要和物理主机的线程数一致 show parameters cpu_count;
查看系统的进程数目,会话数目和最大事务数目分别
set heading off; show parameter processes; show parameter sessions; show parameter transactions;
直接在 v$parameter 视图中查看进程数和会话数
COLUMN NAME FORMAT A32; COLUMN VALUE FORMAT A64; SELECT T.NAME, T.VALUE FROM V$PARAMETER T WHERE NAME in ('sessions', 'processes', 'transactions');
一般讲 processes 的数值根据系统的性能来设置,但是 sessions 和 transactions 和 processes 有一定的换算关系
| Oralce | sessions | transactions |
|---|---|---|
| 11g (11.2.0.4) | 1.5 × processes + 22 | 1.1 × sessions |
| 10g | 1.1 × processes + 5 | 1.1 × sessions |
Oracle 设置对应参数的快速对照表
| 11g | 11g | 10g | 10g | |
|---|---|---|---|---|
| processes | sessions | transactions | sessions | transactions |
| 100 | 172 | 110 | 115 | 110 |
| 128 | 214 | 141 | 146 | 141 |
| 200 | 322 | 220 | 225 | 220 |
| 256 | 406 | 282 | 287 | 282 |
| 300 | 472 | 330 | 335 | 330 |
| 512 | 790 | 563 | 568 | 563 |
| 800 | 1222 | 880 | 885 | 880 |
| 1000 | 1522 | 1100 | 1105 | 1100 |
| 1024 | 1558 | 1126 | 1131 | 1126 |
| 1200 | 1822 | 1320 | 1325 | 1320 |
| 1500 | 2272 | 1650 | 1655 | 1650 |
可以根据上述对应关系表格设置相应的参数
alter system set processes = 1024 scope = both; alter system set sessions = 1568 scope = both; alter system set transactions = 1126 scope = both;
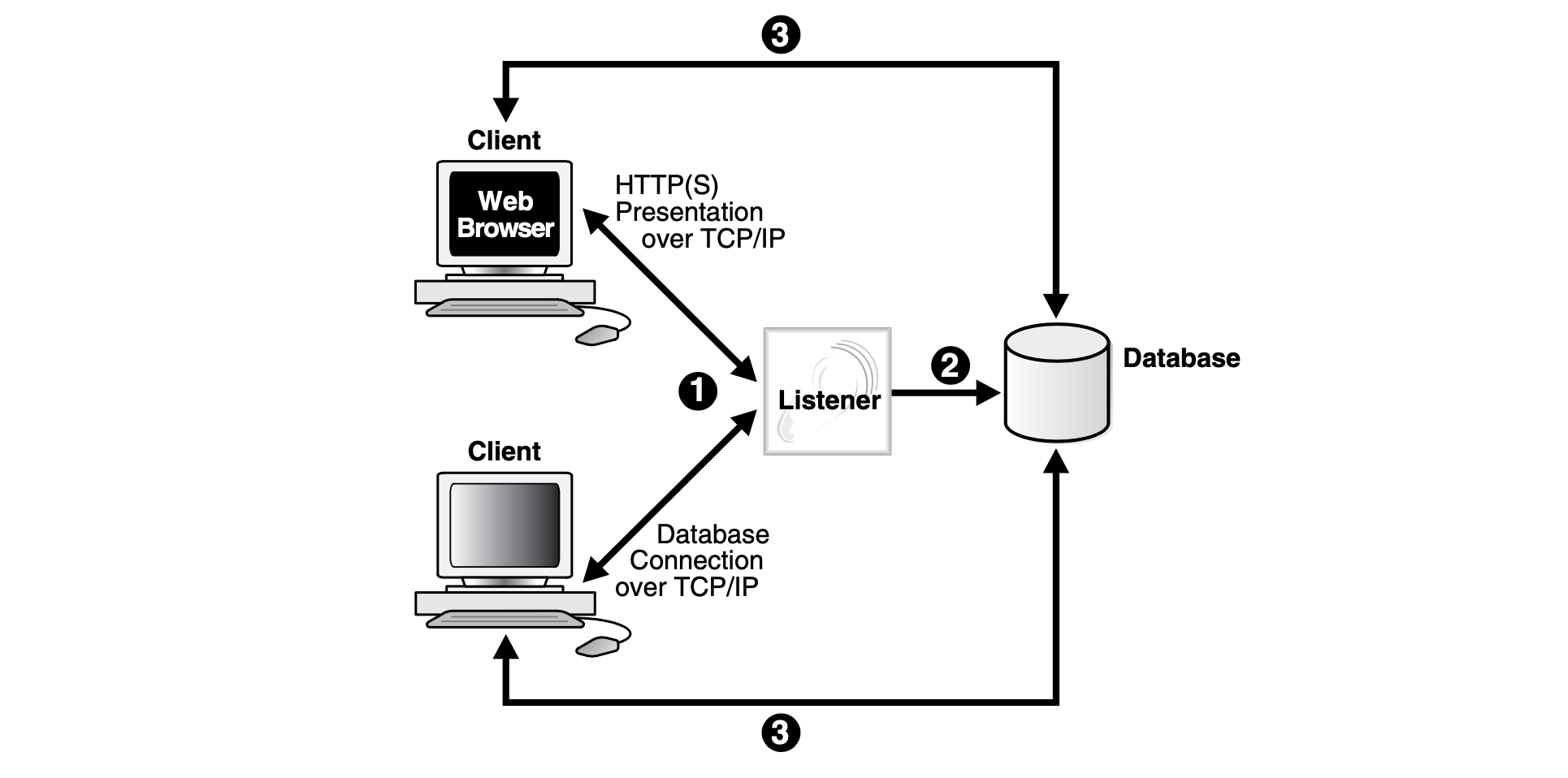
5.4.3 数据库网络架构
Oracle 的网络采取监听模式,客户端可以通过 HTTP 或者 TNS 等协议连接 Oracle 的服务 器本地启动的监听器,通过监听代理来完成和数据库的交互
Oracle 监听的工具主要有以下两个
$ tnsping localhost -- tnsping 工具 TNS Ping Utility for Linux: Version 11.2.0.4.0 - Production on 26-FEB-2020 17:22:33 Copyright (c) 1997, 2013, Oracle. All rights reserved. Used parameter files: /u01/app/oracle/product/11.2.0/dbhome_1/network/admin/sqlnet.ora Used EZCONNECT adapter to resolve the alias Attempting to contact (DESCRIPTION=(CONNECT_DATA=(SERVICE_NAME=))(ADDRESS=(PROTOCOL=TCP)(HOST=127.0.0.1)(PORT=1521))) OK (10 msec) $ lsnrctl status -- lsnrctl 工具 LSNRCTL for Linux: Version 11.2.0.4.0 - Production on 26-FEB-2020 17:22:45 Copyright (c) 1991, 2013, Oracle. All rights reserved. Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=EXTPROC1521))) STATUS of the LISTENER ------------------------ Alias LISTENER Version TNSLSNR for Linux: Version 11.2.0.4.0 - Production Start Date 26-FEB-2020 12:36:36 Uptime 0 days 4 hr. 46 min. 9 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Listener Parameter File /u01/app/oracle/product/11.2.0/dbhome_1/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/ol64-52/listener/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=ol64-52.localdomain)(PORT=1521))) Services Summary... Service "ora11g" has 1 instance(s). Instance "ora11g", status READY, has 1 handler(s) for this service... Service "ora11gXDB" has 1 instance(s). Instance "ora11g", status READY, has 1 handler(s) for this service... The command completed successfully
Oracle 数据库实例的动态监听注册细节
- 如果是先启动监听,后启动数据库实例,则动态监听会自动识别到启动的数据库实 例;
- 在数据库实例正常运行的情况下重启监听,则数据库实例会等很长时间才能在动态 监听中注册成功,大约需要 1 分钟的等待时间
- 如果是先启动数据库实例,后启动监听,效果和 2 一样
- 如果不希望长时间等待动态监听注册的过程,下面命令加速
alter system register;
6 数据库管理
6.1 用户和角色
6.1.1 查看当前用户
show user; select user from dual;
例如:
SQL> show user; USER is "APPLE" SQL> select user from dual; APPLE
6.1.2 创建/解锁用户
create user <username> identified by <password>; alter user <username> account unlock identified by <password>; alter user hr account unlock identified by hr;
6.1.3 删除用户
drop user <username>;
6.1.4 修改用户密码
有时候修改用户密码但是不知道用户的原始密码,可以添加 VALUES 传入的是数据库
加密后的密码字符串
alter user <username> identified by <password>; alter user <username> identified by values <encrypted_password>;
6.1.5 角色和授权
-- 创建角色 create role <rolename> identified by <password>; -- 授权用户 grant all on <schema>.* to <username>; -- 解除授权 revoke all on <schema>.* from <username>;
7 工作流
7.1 日期格式
查看时间相关的参数
show parameters nls;
Oracle 不支持直接修改底层系统的时间格式,但是默认的时间格式为 DD-MON-RR 的
字符串,显示得不是很友好,所以需要使用一些曲线救国的方式来修改日期时间的格式
方案一:在当前会话的启动后直接修改当前会话的时间格式
alter session set nls_date_format = 'YYYY-MM-DD HH24:MI:SS';
方案二:添加环境变量,每次启动 sqlplus 会直接读取环境变量从而达到修改日期格式 的目的
export NLS_DATE_FORMAT='YYYY-MM-DD HH24:MI:SS'
方案三:在选取时间日期字段时显示使用 to_char 函数来格式化时间
select to_char(sysdate, 'YYYY-MM-DD HH24:MI:SS') as now from dual;
7.2 时区
查看数据库的时区
select dbtimezone from dual;
通过 tz_offset 转化数据库的时区和当前会话的时区
SELECT TZ_OFFSET (DBTIMEZONE) AS "Remote Time Zone", TZ_OFFSET (SESSIONTIMEZONE) AS "Local Time Zone" FROM DUAL;
7.3 创建带自增 ID 的表
Oracle 创建自增 ID 分为三个步骤
- 创建表
- 创建自增序列
- 添加更新 ID 值的触发器
CREATE TABLE TB_USERS ( ID NUMBER NOT NULL, AVAILABLE CHAR(1) DEFAULT 'Y' NOT NULL, CREATED_AT DATE DEFAULT SYSDATE NOT NULL, UPDATED_AT DATE DEFAULT SYSDATE NOT NULL, CONSTRAINT TB_USERS_PK PRIMARY KEY (ID) ); CREATE SEQUENCE TB_USERS_ID_SEQ INCREMENT BY 1 START WITH 1 MINVALUE 1 MAXVALUE 999999999; CREATE OR REPLACE TRIGGER TB_USERS_ID_TGR BEFORE INSERT ON TB_USERS FOR EACH ROW WHEN (NEW.ID IS NULL) BEGIN SELECT TB_USERS_ID_SEQ.NEXTVAL INTO :NEW.ID FROM DUAL; END; /
7.4 创建新的表空间以及用户
7.4.1 创建数据储存的目录
Oracle 数据库的表空间的存储目录需要手工创建,注意创建的文件夹要求
oracle:dba 能够读写
mkdir -p /u01/app/oracle/oradata/XE
7.4.2 创建表空间
Oracle 在创建用户前最好为当前用户显示创建表空间,否则创建的新用户会使用默认 的表空间。为了避免这种情况,提前创建默认表空间和临时表空间
-- 创建默认表空间 CREATE TABLESPACE PFILE1 DATAFILE '/u01/app/oracle/oradata/xe/pfile1.dbf' SIZE 128M AUTOEXTEND OFF LOGGING ONLINE PERMANENT EXTENT MANAGEMENT LOCAL AUTOALLOCATE BLOCKSIZE 8K SEGMENT SPACE MANAGEMENT AUTO FLASHBACK ON; -- 创建临时表空间 CREATE TEMPORARY TABLESPACE TFILE1 TEMPFILE '/u01/app/oracle/oradata/xe/tfile1.dbf' SIZE 2048M AUTOEXTEND OFF TABLESPACE GROUP '' EXTENT MANAGEMENT LOCAL UNIFORM SIZE 1M;
7.4.3 创建用户
创建新的用户
drop user avictor cascade; create user avictor identified by secret default tablespace pfile1 temporary tablespace tfile1 profile default account unlock; grant connect to avictor; grant dba to avictor; alter user avictor default role all; grant select any dictionary to avictor; grant select any sequence to avictor; grant select any table to avictor; grant select any transaction to avictor; grant unlimited tablespace to avictor; alter user avictor identified by secret;
使用 sqlplus 测试一下连接是否成功
sqlplus avictor/secret@localhost/xe
7.5 导入/导出数据
7.5.1 导出全部数据库
如果两个数据库的磁盘的物理路径都是相同的,可以指定 full=y 的方式导入所有的
数据库,这种方式导出的表空间会绑定到磁盘上存储的 Datafile 路径
-- 导出所有的表 exp user/pass@host:port/sid FULL=y FILE=data.dmp -- 导入所有的表 imp user/pass@host:port/sid FULL=y FILE=data.dmp
7.5.2 导出用户的数据库
如果要导出某个特定用户的所有数据库,这种方式导出的数据库的表空间文件不会绑定 到磁盘存储的物理位置,使用下面命令可以查看所有的帮忙选项
-- 查看帮助和可选的参数 exp help=y imp help=y
最后新建一个保存参数是文件,这样使用 exp 和 imp 文件时就可以少敲一些命令,这
里将相关参数保存成 options.txt
USERID=system/oracle@host/sid FILE=data.dmp GRANTS=y INDEXES=y CONSTRAINTS=y ROWS=y
导入和导出命令
-- 导出数据库 exp PARFILE=options.txt LOG=export.log OWNER=owner1 -- 导入数据库 imp PARFILE=options.txt LOG=import.log FROMUSER=owner1 TOUSER=owner2
7.6 正则化表达式匹配
Oracle 可以使用 regexp_like 来做正则表达式匹配
SQL> SELECT TABLE_NAME FROM USER_TAB_COMMENTS WHERE regexp_like(TABLE_NAME, '^PRDT'); TABLE_NAME ----------------------------- PRDT_DIC PRDT_DIC_ALL_V PRDT_DIC_BOM PRDT_DIC_CODE_RULE PRDT_DIC_EXT01 PRDT_DIC_EXT02 PRDT_DIC_PROCESS PRDT_DIC_PROCESS_ALL PRDT_DIC_PROCESS_DEVICE_WORK PRDT_KIND_TYPE PRDT_LIST_TYPE PRDT_PROCESS_ACT_DIC PRDT_PROCESS_DIC PRDT_PROCESS_RES_DIC
7.7 获取序列值
创建序列
CREATE SEQUENCE SEQ_GLOBAL_ID START WITH 10000 INCREMENT BY 1;
NEXTVAL 获取下一个序列值,同时自增, CURRVAL 获取当前序列值,单不自增。
SQL> SELECT SEQ_GLOBAL_ID.NEXTVAL FROM DUAL; 10000 SQL> SELECT SEQ_GLOBAL_ID.NEXTVAL FROM DUAL; 10001 SQL> SELECT SEQ_GLOBAL_ID.CURRVAL FROM DUAL; 10001 SQL> SELECT SEQ_GLOBAL_ID.CURRVAL FROM DUAL; 10001 SQL>
7.8 限制查询结果的行数
使用 ROWNUM 在条件语句中限制
SELECT ID FROM EMPLOYEE WHERE ROWNUM < 100;
7.9 删除表中重复的行数据
Oracle 里面每行都有一个 ROWID 的伪列,即使两行的数据是相同的, ROWID 也是
唯一的。
SELECT DISTINCT MYID FROM T_EMPLOYEE_BASE E1 WHERE ROWID != ( SELECT MAX(ROWID) FROM T_EMPLOYEE_BASE E2 WHERE E1.MYID = E2.MYID );
将 SELECT 修改成 DELETE 即可删除重复行。
7.10 查看数据库磁盘容量
7.11 查看 Query 的执行时间
查看单个 Query 执行计时直接开启 set timing on 选项就可以看到
SQL> select count(*) from t_log; COUNT(*) ---------- 85718 SQL> set timing on SQL> select count(*) from t_log; COUNT(*) ---------- 85718 Elapsed: 00:00:00.04 SQL> set timing off
查询多条 query 语句的计时需要借助计时器
SQL> timing start mytimer; SQL> select count(*) from t_log; COUNT(*) ---------- 85718 SQL> timing show mytimer; timing for: mytimer Elapsed: 00:00:00.04 SQL> select max(myid) from t_log; MAX(MYID) ---------- 103234 SQL> timing stop mytimer; timing for: mytimer Elapsed: 00:00:00.07 SQL>
7.12 字符串拼接的聚合函数
oracle 10g 和 11g 的字符串拼接函数不是一样的,10g 中使用 WM_CONCAT() 聚合函
数,而在 11g 中需要使用 LISTAGG() 聚合函数。两者的语法也是不太一样的
10g 的使用方式
SELECT A.CONSTRAINT_NAME, WM_CONCAT (TO_CHAR(A.COLUMN_NAME)) AS COLNAMES FROM USER_CONS_COLUMNS A, USER_CONSTRAINTS B WHERE A.CONSTRAINT_NAME = B.CONSTRAINT_NAME AND UPPER(B.CONSTRAINT_TYPE) = 'U' AND UPPER(A.TABLE_NAME) = UPPER('tabname') GROUP BY A.CONSTRAINT_NAME;
11g 的使用方式
SELECT A.CONSTRAINT_NAME, LISTAGG (A.COLUMN_NAME, ',') WITHIN GROUP (ORDER BY A.POSITION) AS COLNAMES FROM USER_CONS_COLUMNS A, USER_CONSTRAINTS B WHERE A.CONSTRAINT_NAME = B.CONSTRAINT_NAME AND UPPER(B.CONSTRAINT_TYPE) = 'U' AND UPPER(A.TABLE_NAME) = UPPER('tabname') GROUP BY A.CONSTRAINT_NAME;
8 常见问题
8.1 客户端和服务器字符集不一致
首先查看一下服务器中的编码格式,最好设置服务器的编码格式为 Unicode
SELECT USERENV('language') FROM DUAL;
SQL> SELECT USERENV('language') FROM DUAL;
AMERICAN_AMERICA.AL32UTF8
根据服务器的编码格式来修改客户端的编码格式
# 将客户端修改成英文的 Unicode 码 export NLS_LANG="AMERICAN_AMERICA.AL32UTF8" # 或者直接修改成中文的 Unicode 码,解决中文乱码 export NLS_LANG="SIMPLIFIED CHINESE_CHINA.AL32UTF8"
8.2 将服务器字符集从 UTF8 强转成 GBK
修改数据库字符集最好放在在安装数据库的最初阶段,如果修改一个已经运行的数据库 可能会发生一些不可预料的错误
-- 本操作必须使用 DBA 权限 CONNECT SYS/oracle AS SYSDBA; -- 关闭连接断开所有已经建立的链接 SHUTDOWN IMMEDIATE; STARTUP MOUNT; -- 预先设置处理工作 ALTER SYSTEM ENABLE RESTRICTED SESSION; ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0; ALTER SYSTEM SET AQ_TM_PROCESSES=0; ALTER DATABASE OPEN; -- ALTER DATABASE CHARACTER SET ZHS16GBK ; -- *ERROR at line 1: -- ORA-12712: new character set must be a superset of old character set -- 报字符集不兼容,此时下 INTERNAL_USE 指令不对字符集超集进行检查: ALTER DATABASE CHARACTER SET INTERNAL_USE ZHS16GBK; -- 重启数据库 SHUTDOWN IMMEDIATE; STARTUP;
查看当前数据库的字符集
COLUMN PROPERTY_NAME FORMAT A32 HEADING 'Name'; COLUMN PROPERTY_VALUE FORMAT A32 HEADING 'Value'; COLUMN DESCRIPTION FORMAT A80 HEADING 'Description' TRUNCATE; SELECT PROPERTY_NAME, PROPERTY_VALUE, DESCRIPTION FROM DATABASE_PROPERTIES WHERE PROPERTY_NAME LIKE 'NLS_%';
8.3 ORA-00904: "POLTYP": invalid identifier
客户端版本如下:
Export: Release 11.2.0.2.0 - Production on Thu Sep 12 00:56:51 2019 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved.
服务器数据版本如下:
Connected to: Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 - 64bit Production With the Partitioning, OLAP, Data Mining and Real Application Testing options
在使用以下 11g 的 exp 客户端程序导出 10g 服务器数据出现问题以下:
EXP-00008: ORACLE error 904 encountered ORA-00904: "POLTYP": invalid identifier EXP-00000: Export terminated unsuccessfully
查了一下在不动数据库的前提下解决这种问题最好方法是: 将导出客户端换成 10g
8.4 ORA-21561: OID generation failed
数据库的主机名解析错误
$ hostname Jesenia.local $ ping Jesenia.local ping: cannot resolve Jesenia.local: Unknown host $ cat /etc/hosts ## # Host Database # # localhost is used to configure the loopback interface # when the system is booting. Do not change this entry. ## 127.0.0.1 localhost 255.255.255.255 broadcasthost ::1 localhost
在 hosts 文件结尾追加当前主机的解析地址即可
sudo echo "127.0.0.1 $(hostname)" >> /etc/hosts
9 sqlplus
Oracle 的 sqlplus 是与 Oracle 数据库进行交互的客户端工具,借助 sqlplus 可以查 看、修改数据库记录。在 sqlplus 中,可以运行 sqlplus 命令与 SQL 语句。
9.1 Instantclient 安装
在 mac 和 linux 系统中如果只是想要安装 sqlplus 命令行工具,需要安装 Instantclient 工具
9.1.1 macOS
mac 下的 Oracle 安装需要下载几个 Instantclient 安装包
- instantclient-basic-macos.x64-11.2.0.4.0.zip
- instantclient-sdk-macos.x64-11.2.0.4.0.zip
- instantclient-sqlplus-macos.x64-11.2.0.4.0.zip
解压安装包
unzip instantclient-basic-macos.x64-11.2.0.4.0.zip unzip instantclient-sdk-macos.x64-11.2.0.4.0.zip unzip instantclient-sqlplus-macos.x64-11.2.0.4.0.zip
解压后生成一个 instantclient_11_2 文件夹,直接拷贝到安装的文件夹中
sudo mkdir -p /usr/local/java sudo cp -r instantclient_11_2 /usr/local/java
建立软连接
cd /usr/local/java/instantclient_11_2 mkdir lib ln -s libclntsh.dylib.11.1 libclntsh.dylib ln -s libocci.dylib.11.1 libocci.dylib ln -s $PWD/{libclntsh.dylib.11.1,libnnz11.dylib,libociei.dylib} lib/ ln -s $PWD/{libsqlplus.dylib,libsqlplusic.dylib} lib/
添加环境变量到 .bashrc 中
export SQLPATH="/usr/local/java/instantclient_11_2" export PATH="${SQLPATH}:$PATH" export DYLD_LIBRARY_PATH="${SQLPATH}/lib${DYLD_LIBRARY_PATH:+:${DYLD_LIBRARY_PATH}}"
9.1.2 Linux
需要下载的安装文件
- instantclient-basic-linux.x64-11.2.0.4.0.zip
- instantclient-sdk-linux.x64-11.2.0.4.0.zip
- instantclient-sqlplus-linux.x64-11.2.0.4.0.zip
解压安装包
unzip instantclient-basic-linux.x64-11.2.0.4.0.zip unzip instantclient-sdk-linux.x64-11.2.0.4.0.zip unzip instantclient-sqlplus-linux.x64-11.2.0.4.0.zip
构建目录结构
[ ! -d /usr/local/java ] && mkdir -p /usr/local/java sudo mv instantclient_11_2 /usr/local/java cd /usr/local/java/instantclient_11_2 sudo mkdir lib
建立软连接
ln -s libclntsh.so libclntsh.so.11.1
ln -s libocci.so libocci.so.11.1
cd /usr/lib
ln -s /usr/local/java/instantclient_11_2/libclntsh.so libclntsh.so.11.1
ln -s /usr/local/java/instantclient_11_2/libocci.so libocci.so.11.1
ln -s /usr/local/java/instantclient_11_2/libnnz11.so libnnz11.so
ln -s /usr/local/java/instantclient_11_2/libociei.so libociei.so
ln -s /usr/local/java/instantclient_11_2/libocijdbc11.so libocijdbc11.so
ln -s /usr/local/java/instantclient_11_2/libsqlplusic.so libsqlplusic.so
ln -s /usr/local/java/instantclient_11_2/libsqlplus.so libsqlplus.so
添加环境变量
export SQLPATH="/usr/local/java/instantclient_11_2" export PATH=${SQLPATH}${PATH:+:${PATH}} export LD_LIBRARY_PATH=${SQLPLUS}/lib${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
9.2 添加 Readline 的支持
sqlplus 本身不支持 Readline 的特性,但可以通过安装 rlwrap 来将 Readline 特性 添加到 sqlplus 中
# mac brew install rlwrap # ubuntu sudo apt-get install -y rlwrap
通过 rlwrap 来启动 sqlplus
rlwrap -c sqlplus user/pass@host/sid
或者直接定义一个别名
alias sp='rlwrap -c sqlplus'
9.3 启动 sqlplus
第一种登录方式的命令如下
sqlplus username/password@hostname:port/service_id
登录过后可以看到成功的登录界面
第二种登录方式需要使用 tnsnames.ora 这种格式,下面是 Oracle Client 提供的默
认的配置
# This is a sample tnsnames.ora that contains the NET8 parameters that are
# needed to connect to an HS Agent
hsagent =
(DESCRIPTION=
(ADDRESS=(PROTOCOL=tcp)(HOST=localhost)(PORT=1521))
(CONNECT_DATA=(SID=hsagent))
(HS=)
)
熟悉了 tnsnames.org 这种格式后就可以编写相应的登录命令,具体方式如下:
sqlplus username/password@"(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)(HOST=hostname)(PORT=1521)))(CONNECT_DATA=(SERVER=DEDICATED)(SERVICE_NAME=service_id)))"
当命令中的密码字段中含义有 @ 字段时需要将 password 字段用双引号包起来,如下:
sqlplus user/\"my@password\"@hostname:port/service_id
9.4 启动配置
在启动 sqlplus 时需要预先设置一些启动的基本配置,例如启动的每行显示的字符数量, 显示是否折行,分页大小配置等。sqlplus 启动配置文件通常在下面两位置中
$ORACLE_HOME/sqlplus/admin/glogin.sql$SQLPATH/glogin.sql
下面是我的配置
-- glogin.sql -- set underline off -- set verify off -- set trimout on -- set trimspool on set tab off set wrap off set linesize 32767 set pagesize 9999 -- responsive linesize host echo "set linesize $(stty -a | head -n 1 | cut -d';' -f3 | cut -d' ' -f3)" > .tmp.sql @.tmp.sql host rm .tmp.sql -- macOS use -- host echo "set linesize $(stty -a | head -n 1 | cut -d';' -f3 | cut -d' ' -f2)" > .tmp.sql -- @.tmp.sql -- host rm .tmp.sql -- add user and sid to prompt column global_name new_value gname set termout off select '('|| lower(user || '@' || global_name) || ')' || chr(10) || 'SQL> ' as global_name from global_name; set sqlprompt '&gname' set termout on -- change date format alter session set nls_date_format = 'yyyy-mm-dd hh24:mi:ss';
9.5 sqlplus 的常见命令
- 执行本地 SQL 脚本:
start filename或者@ filename - 在 sqlplus 里面执行 shell 命令:
host cmd - 将 sqlplus 执行的命令存成本地文件:
save filename - 装载本地 SQL 脚本,但不立即执行:
get filename - 执行最后一条 SQL 语句:
/ - 打印最后执行的 SQL 语句:
L - 结果输出到文件:
spool filename - 查看/修改 sqlplus 的环境变量:
show/set variablename, 使用show all打印 所有变量值
9.6 在 sqlplus 中使用变量
9.6.1 定义和使用变量
定义的变量只在一个 sqlplus 的会话期间有效
-- 定义一个变量 define var = text; -- 读取用户输入,将用户输入放到变量中 accept var; -- 在变量名前面添加 & 来使用变量 define mydate = 01-FEB-98; select '&mydate' from dual;
下面使用一个使用例子
SQL> DEFINE MYDATE = 01-FEB-98; SQL> SELECT '&MYDATE' FROM DUAL; 原值 1: SELECT '&MYDATE' FROM DUAL 新值 1: SELECT '01-FEB-98' FROM DUAL '01-FEB-98' --------------------------- 01-FEB-98 SQL>
9.6.2 将列值赋给变量
具体语法如下:
column colname new_value var
使用示例
SQL> column len1 new_value l1 SQL> select max(length(t.table_name)) as len1 from user_tab_comments t; LEN1 ---------- 29 SQL> select &l1 from dual; old 1: select &l1 from dual new 1: select 29 from dual 29 ---------- 29 SQL>
9.7 执行 SQL 脚本的方法
执行没有参数的 SQL 脚本
# 执行 script.sql 脚本后退出, echo 'exit' | sqlplus -S user/pass@host:port/sid @script.sql # 使用重定向执行 script.sql 脚本 sqlplus -S user/pass@host:port/sid < script.sql # 使用重定向执行脚本并追加方式输出日志 sqlplus -S user/pass@host:port/sid < script.sql >> /tmp/sqlplus.log # .sql 文件后缀名不是必须的,例如下面的两句是同样效果的 echo 'exit' | sqlplus -S user/pass@host:port/sid @script.sql echo 'exit' | sqlplus -S user/pass@host:port/sid @script
将参数传入 script.sql 脚本,在调用脚本时直接将参数写到后面,见下面的例子
echo 'exit' | sqlplus -S user/pass@host:port/sid @script.sql arg1 arg2
然后在脚本中使用 &1 引用第一个参数, &2 引用第二个参数,以此类推
define arg1 = &1 select '&arg1' from dual;
9.8 打开/关闭终端输出
set termout off; -- do a lot of parepare work set termout on;
10 杂项
10.1 Oracle 基本常识
- Oracle 数据库中语句 不区分大小写, 10g 中包括登录名的用户名和密码都是不区 分大小写的,当然这个是可以设置的
- 一般关键字要求大写,但是不大写也没关系
Oracle 的 select 语句必须要加 from 语句,如果没有的话使用 dual 伪表
select 5/2 from dual
10.2 Ubuntu 18.04 安装 Oracle 11g XE 数据库
如果有 Oracle 11g XE 版本的 deb 包,可以使用如下方式安装,否则最好参考官方的 手册来安装
# 安装依赖包 sudo apt-get install -y libaio1 libaio-dev net-tools # 安装软件包 dpkg --install /assets/oracle-xe_11.2.0-1.0_amd64.deb
10.3 判断回滚段竞争的 SQL 语句
当 Ratio 大于 2 时存在回滚段竞争,需要增加更多的 回滚段
select rn.name as "Name", rs.gets as "Gets", rs.waits as "Waits", (rs.waits / rs.gets) * 100 as "Ratio (%)" from v$rollstat rs, v$rollname rn where rs.usn = rn.usn;
10.4 判断恢复日志竞争的 SQL 语句
Immediate Contention 或 Wait Contention 的值大于 1 时存在竞争
column name format a20; select name, round(100 * decode(sign(t.immediate_gets - t.immediate_misses), 1, t.immediate_misses / (t.immediate_gets - t.immediate_misses), 0), 2) as "Immediate Contention (%)", round(100 * decode(sign(t.gets - t.misses), 1, t.misses / (t.gets - t.misses), 0), 2) as "Wait Contention (%)" from v$latch t where lower(name) in ('redo copy', 'redo allocation');
10.5 判断表空间碎片
如果最大空闲空间占总空间很大比例则可能不存在碎片,如果比例较小,且有许多空闲 空间,则可能碎片很多
select t.tablespace_name, sum(t.bytes), max(t.bytes), count(*), max(t.bytes) / sum(t.bytes) radio from dba_free_space t group by t.tablespace_name order by t.tablespace_name;
10.6 确定命中排序域的次数
select t.name, t.value from v$sysstat t where lower(t.name) like 'sort%';
10.7 查看当前 SGA 值
select * from v$sga;
10.8 确定高速缓冲区命中率
如果命中率低于 70%,则应该加大 init.ora 参数中的 db_block_buffer 的值
select 100 * (1 - ((physical.value - direct.value - lobs.value) / logical.value)) as "Buffer Cache Hit Ratio (%)" from v$sysstat physical, v$sysstat direct, v$sysstat lobs, v$sysstat logical where physical.name = 'physical reads' and direct.name = 'physical reads direct' and lobs.name = 'physical reads direct (lob)' and logical.name = 'session logical reads';
10.9 确定共享池中的命中率
如果 ratio1 大于 1 时,需要加大共享池,如果 ratio2 大于 10%时,需要加大共享
池 shared_pool_size
select sum(pins) as pins, sum(reloads) as reloads, (sum(reloads) / sum(pins)) * 100 as ratio1 from v$librarycache; select sum(gets) as gets, sum(getmisses) as getmisses, (sum(getmisses) / sum(gets)) * 100 as ratio2 from v$rowcache;
10.10 数据库参数属性
column property_name format a25; column property_value format a30; column description format a100; select * from database_properties; select * from v$version;
10.11 求当前会话的 SID, SERIAL#
select sid, serial# from v$session where audsid = sys_context('userenv', 'sessionid');
10.12 闪回表
闪回表需要数据库和表空间都开启了闪回模式
SQL> alter table t1 enable row movement; Table altered. SQL> drop table t1; Table dropped. SQL> flashback table t1 to before drop; Flashback complete. SQL> select count(*) from t1 as of timestamp to_date('20201220 17:00:00', 'yyyymmdd hh24:mi:ss'); COUNT(*) ---------- 87188 SQL> select count(*) from t1 as of timestamp to_date('20201220 17:04:00', 'yyyymmdd hh24:mi:ss'); COUNT(*) ---------- 298
10.13 追溯其它会话
通过 set_sql_trace_in_session 包来追溯其它会话
-- 当前会话 sid SELECT USERENV('sid') FROM DUAL; -- 查看当前默认的追溯文件位置 SELECT VALUE FROM V$DIAG_INFO WHERE NAME LIKE 'Default%'; SELECT SID, SERIAL#, PROGRAM FROM V$SESSION WHERE PROGRAM like '%sqlplus%'; -- 开启其它会话的追溯文件 execute dbms_system.set_sql_trace_in_session(5,131,true); -- 关闭其它会话的追溯文件 execute dbms_system.set_sql_trace_in_session(5,131,false); -- 查看追溯会话的 spid, 找追溯文件 SELECT B.SPID FROM V$SESSION A, V$PROCESS B WHERE A.PADDR = B.ADDR AND A.SID = 5 AND A.SERIAL# = 131;
通过 tkprof 来分析会话的运行资源消耗数
tkprof ora11g_ora_10868.trc d:\a.txt
11 参考链接
- Oracle Database 11g Release 2 在线文档
- Oracle 11g Release 2 文档离线 - 点击后下载得到 Zip 包
- 2 Day DBA - 《两天数据库管理员》
- Oracle Database Concepts, PDF - 《Oracle 数据库概念》
- Oracle Database SQL Reference - 《Oracle 数据库 SQL 参考手册》 可以查看 SQL 内置函数
- Vitaliy Mogilevskiy
